Вы добавляете все интересные вам ссылки в закладки браузера, а
интересные посты — в сохранёнки Телеграма? Может быть, даже снабжаете их
своими комментариями, но получается «свалка», в которой почти невозможно
что-то найти?
Эта инструкция поможет вам создать no-code систему для
автоматической классификации и обработки заметок, постов, статей и видео с помощью
AI. Система поможет вам формировать хорошо структурированную
личную базу данных. Без лишних усилий и раздумий о том, куда скинуть
ссылку, пост или свои собственные мысли — причем так, чтобы потом это
было легко искать.
В качестве интерфейса такой системы я использую Telegram, а в качестве no-code платформы для реализации — сервис Make.com, который имеет бесплатный тариф на 1000 операций в месяц, что обычно достаточно для этой личной цели.
В результате автоматизации вы сможете скидывать в Telegram-бот следующие основные виды информации (которые будем называть записями):
- Свои голосовые заметки. Их обработка описана в
первой части статьи.
- Разные виды гиперссылок. Если ссылка в вашем тексте
одна, то система по ссылке прочитает всю веб-страницу или
google-документ или даже сделает транскрипт видео. И выделит из этого
текста главную информацию.
- Любые Telegram-посты и сообщения. Система увидит, чужой ли это пост или ваш собственный текст, и учтет это при классификации записи в базе знаний.
Разумеется, по ходу дела вы можете предусмотреть и какие-то свои типы записей (входящей информации).
2. Сценарий наполнения личной базы знаний: инструкция
Если вы новичок в Make, то для начала выполните первые 2 пункта инструкции из первой части — сохранение сообщения из Telegram в Google-таблице (если вы знакомы с базами данных, вместо Google Sheet можете сразу взять Supabase).
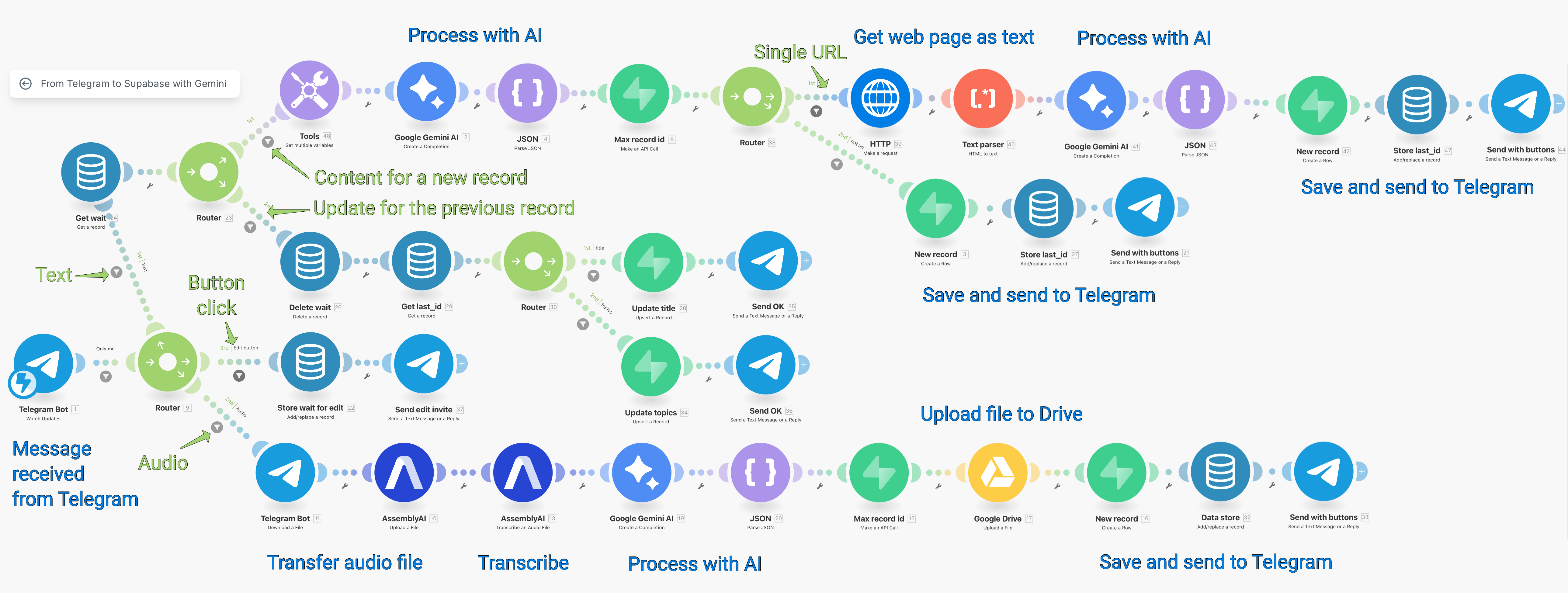
После этого вы будете готовы реализовать хотя бы некоторые ветки из этого разветвленного сценария, о котором пойдет речь ниже:
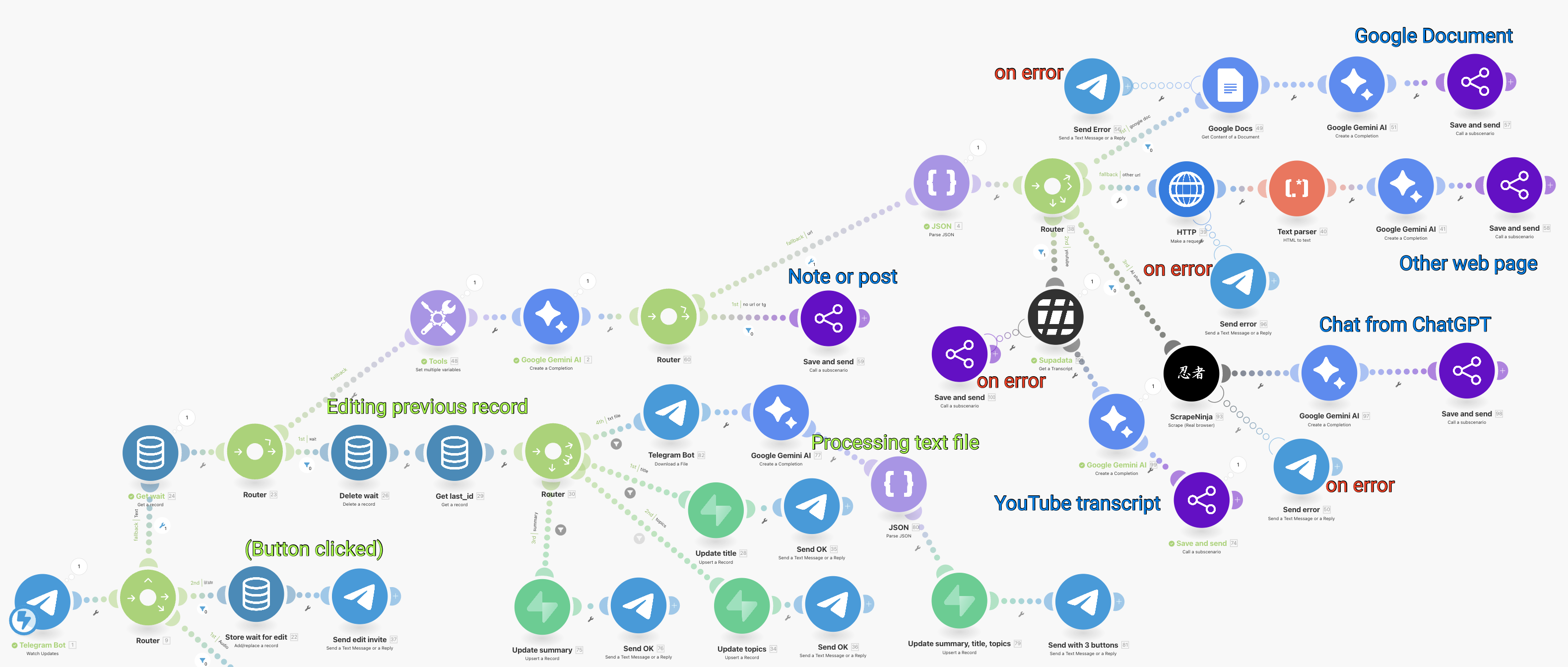
В этой статье я разберу верхнюю часть сценария — все, что не связно с созданием новой записи в базе знаний, а не с редактированием предыдущей записи.
2.7. Первичная классификация и сохранение записей
Итак, допустим, что на вход сценария подается текстовое сообщение, которое может быть просто текстом (например, телеграм-постом) или же содержать требующий отдельных действий адрес веб-страницы, документа или видео.
Я делаю это через Gemini 2.0 Flash с таким промптом (температуру в данном случае лучше ставить равной 0, чтобы ИИ не проявлял креативность). Если это длинный текст, то здесь же он саммаризируется. Если в тексте нет отдельной ссылки, которая будет обработана далее, то здесь же определяются категории записи.
Дальше сценарий разветвляется в зависимости от того, нужно ли обрабатывать выделенную ИИ «главную» ссылку или нет:

Здесь видно, что сохранение в базу знаний делается в особом блоке Call a subscenario. Конкретные блоки внутри этого подсценария уже объяснялись в первой части:
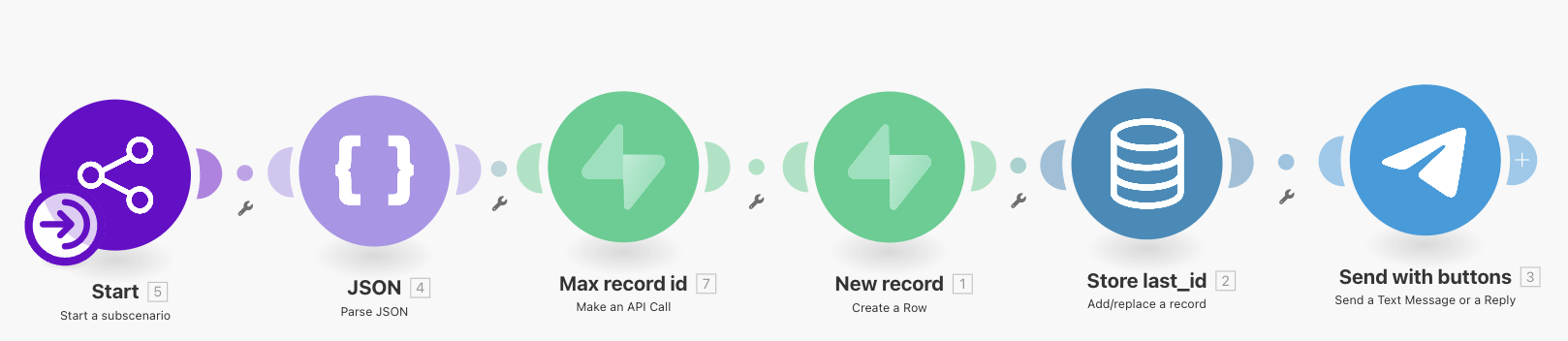
Использование подсценариев помогает избежать дублирований блоков (а чем плохо дублирование, см. ниже в разделе 3.1).
A чтобы избежать дублирования текстов внутри отличающихся блоков, в блоке Set multiple variables я устанавливаю две переменных — основная часть многих промптов и тематические категории для промптов (их нередко приходится дополнять). Там же — две вот такие полезные переменные:
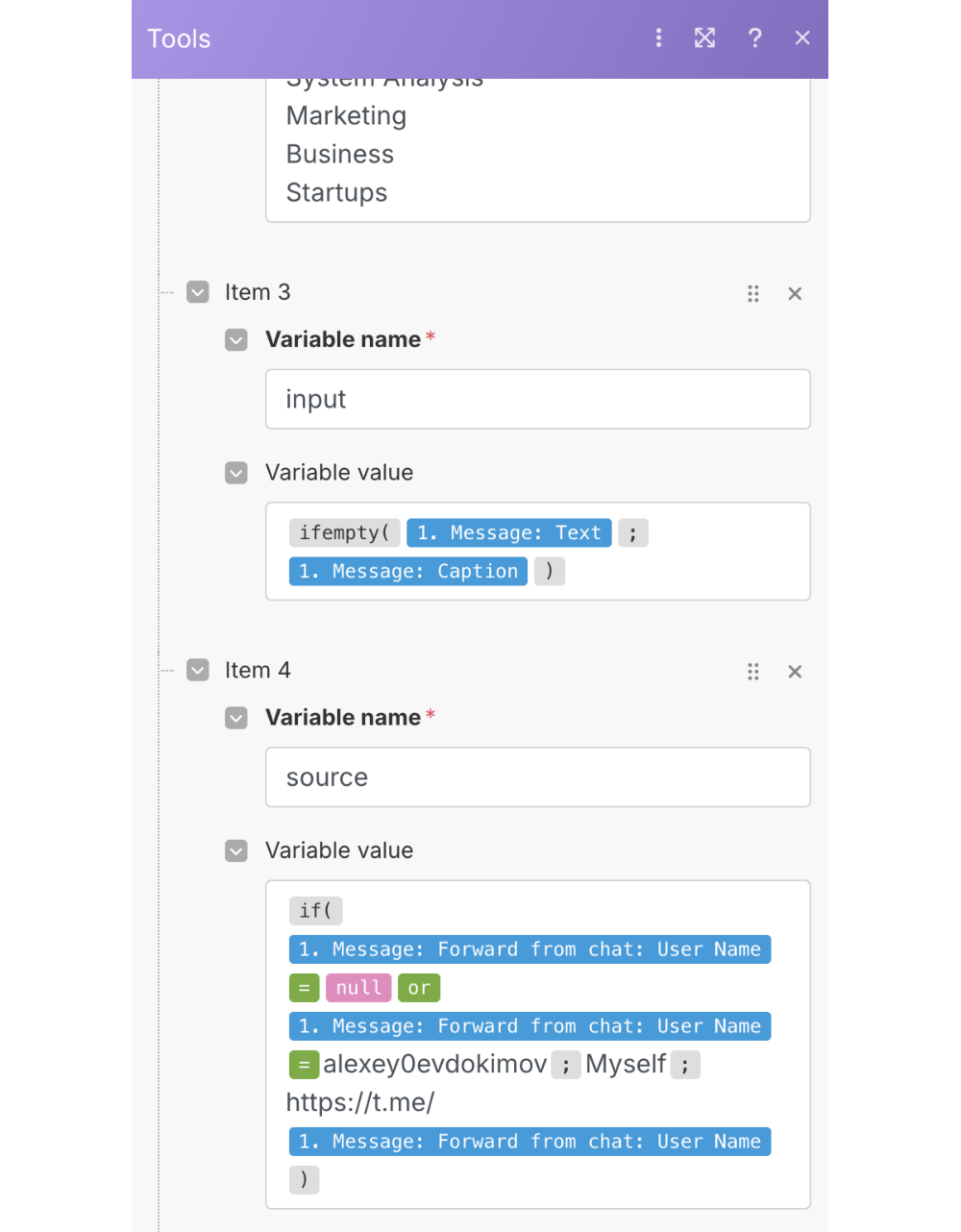
Переменная input нужна, поскольку многие посты в телеграме содержат картинки, и тогда их текст находится в Caption, а не в Text. А переменная source — чтобы отличать свои заметки от чужих постов как в промпте, так и в самой базе знаний.
2.8. Парсинг веб-страниц трех типов
Три ветви сценария, которые соответствуют разным типам веб-страниц, похожи. Они завершаются вызовом того же самого подсценария, а перед ним — блок запроса к ИИ (Gemini).
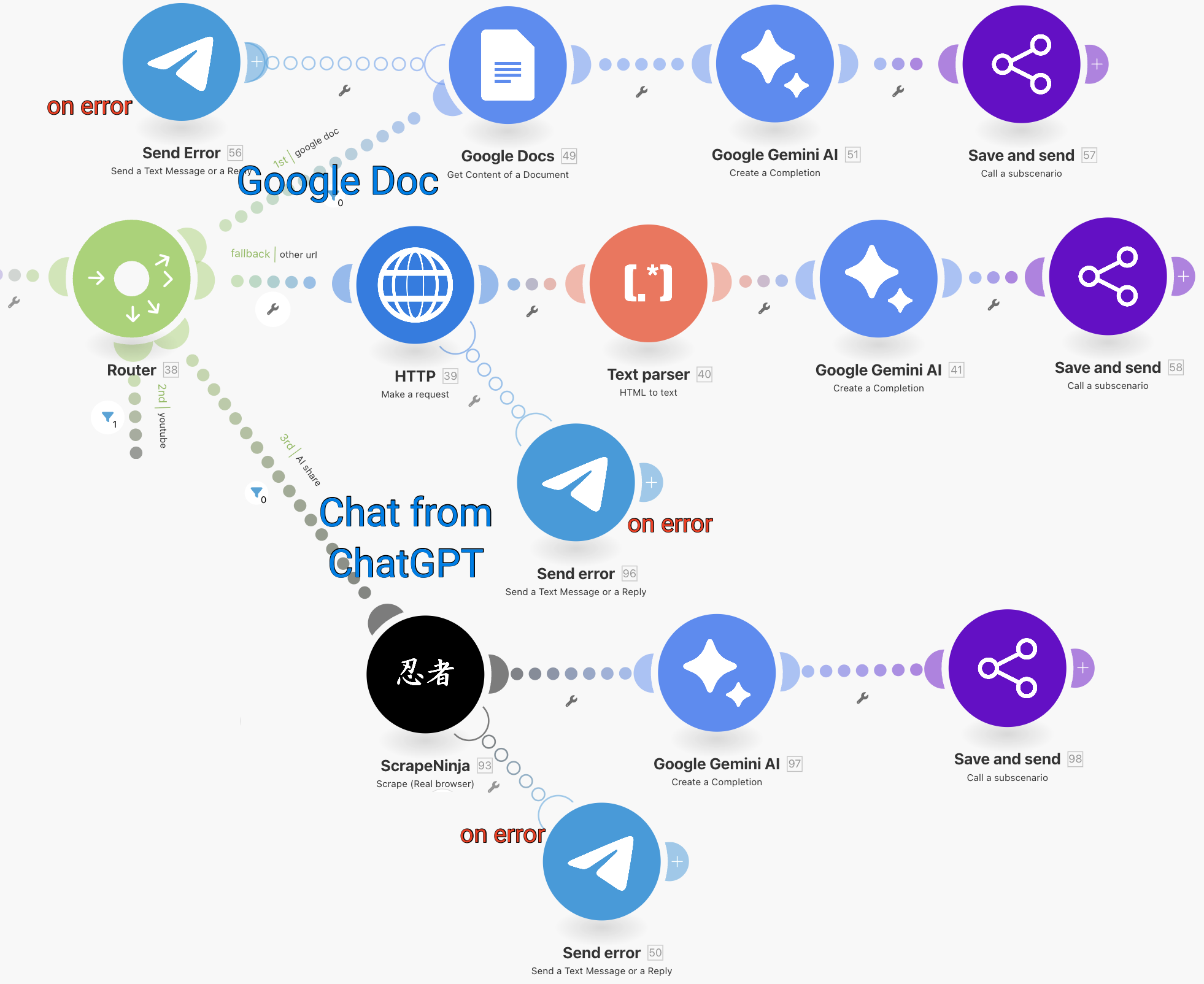
В трех блоках Gemini промпты немного отличаются, поэтому я не стал вносить этот блок внутрь подсценария. В частности, гугл-документы могут содержать информацию, связанные с моей работой или личными проектами, поэтому в промпт там добавлены соответствующие категории.
Также во всех ветвях похожи блоки сообщений в телеграм, которые добавлены к другим блокам как Error handlers. Они выглядят примерно так:
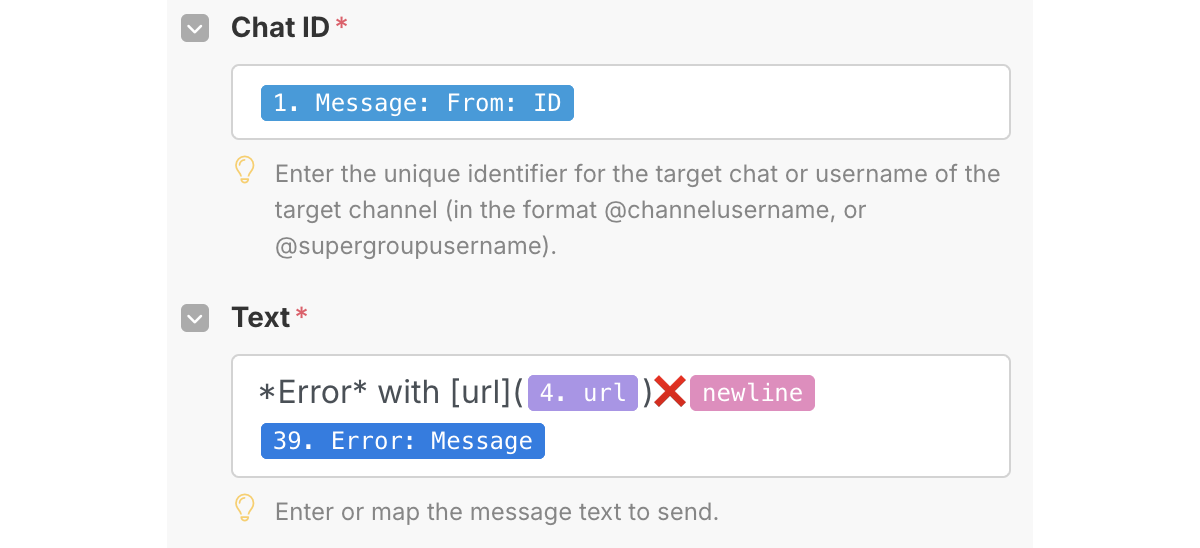
Теперь разберем, чем эти 3 ветви отличаются.
Для преобразования HTML в текст в Make есть даже функция (stripHTML). Но поскольку результат мне все равно нужен 2 раза, пришлось бы под эту функцию все равно создавать блок (Set variable); поэтому сэкономить одну операцию не получилось бы, и я оставил блок Text Parser.
Еще к промпту Gemini в данном случае стоит добавить такую
инструкцию:
The %Text% was already purged of HTML markup but can contain
irrelevant information (website structure) before and after the main
content. Before %Actions%, find where the main content of the text
begins and ends, then process the main content only.
Однако есть проблема: таким прямым способом хорошо парсятся лишь веб-страницы, которые хотят индексироваться в поисковиках. А вот если страница не предназначена для SEO, она запросто может содержать только JavaScript. Этот подход называется CSR (Client-Side Rendering). HTML-контент, который видит пользователь, туда подгружается лишь через некоторое время.
Страницы от чат-ботов как раз CSR — результат HTTP request содержит только скрипты, а не контент.
Для ссылок вида https://chatgpt.com/share/… и для других CSR-страниц вышеуказанная проблема решается специальными сервисами, которые имитируют браузер, ждут подгрузки HTML-контента и возвращают через API запрошенный текст из этого контента.
Я использовал блок сервиса ScrapeNinja. Этот веб-скрейпер доступен через два агрегатора API — apiroad.net и rapidapi.com, но для подключения в Make нужен ключ именно от rapidapi. Бесплатного лимита (50 CSR-страниц в месяц) для меня хватает.
Кстати, если для обычных HTML-страниц качества текста от Text Parser вам будет не хватать, этот же блок ScrapeNinja можно использовать и для таких страниц — в этом случае лимит 500 в месяц. И, в отличие от Text Parser, можно самостоятельно отфильтровать ненужный текст с тех сайтов, страницы с которых вы часто сохраняете.
Для страниц вида https://chatgpt.com/share/… я нашел, что JavaScript загружает контент в элемент с id=“thread” (т.е. этот элемент есть в браузере, но отсутствует в ответе HTTP request):

Поэтому в блоке ScrapeNinja / Scrape (real browser) нужно указать такой CSS selector: #thread
А чтобы извлечь текст из HTML, в ScrapeNinja нужен т.н. “extractor” — кусок JavaScript-кода, обращающийся к cheerio — к самой популярной библиотеке для обработки HTML. Среди примеров в интернете я нужного extractor-а не нашел, спец. инструмент для написания extractor мне не подошел, но совместно с GPT-4.1 я написал следующий код, который и вам рекомендую:
function extract(html, cheerio) {
const $ = cheerio.load(html);
const elements = $(‘div, p’);
const texts = elements.map((i, el) =>
$(el).text().trim()).get();
return texts.filter(Boolean).join(‘\n’);
}
В этом коде предполагается, что текст находится внутри элементов <div> (как в случае ChatGPT) или элементов <p> (как в случае Perplexity). К сожалению, в случае страницы с чатом Perplexity задачу так просто решить не получается, поскольку при первом запросе с неизвестного браузера Perplexity выдает вот такой попап, а контента не отдает.
Замечу, что для отладки ScrapeNinja под нужный сайт совсем не обязательно тратить лимиты в Make.com — лучше воспользоваться их sandbox-ом.
Наконец, нередко нужен еще один тип веб-страницы — это Google-документ. Например, именно в гугл-документ легко экспортируются чаты в gemini.google.com и результаты Deep Research с Gemini.
Блок Google Docs, конечно, есть в Make, и он не требует API-ключей или других сложностей, описанных в первой части для записи в Google Drive. Здесь есть лишь одна небольшая трудность: из гиперссылки на документ нужно получить Document ID (т.е. строку без слешей). Однако функцию для этого преобразования удобно сделать с помощью AI, встроенного в сам Make. Не всегда он работает хорошо, но в данном случае выдал корректный результат (пусть и громоздкий, без regex):
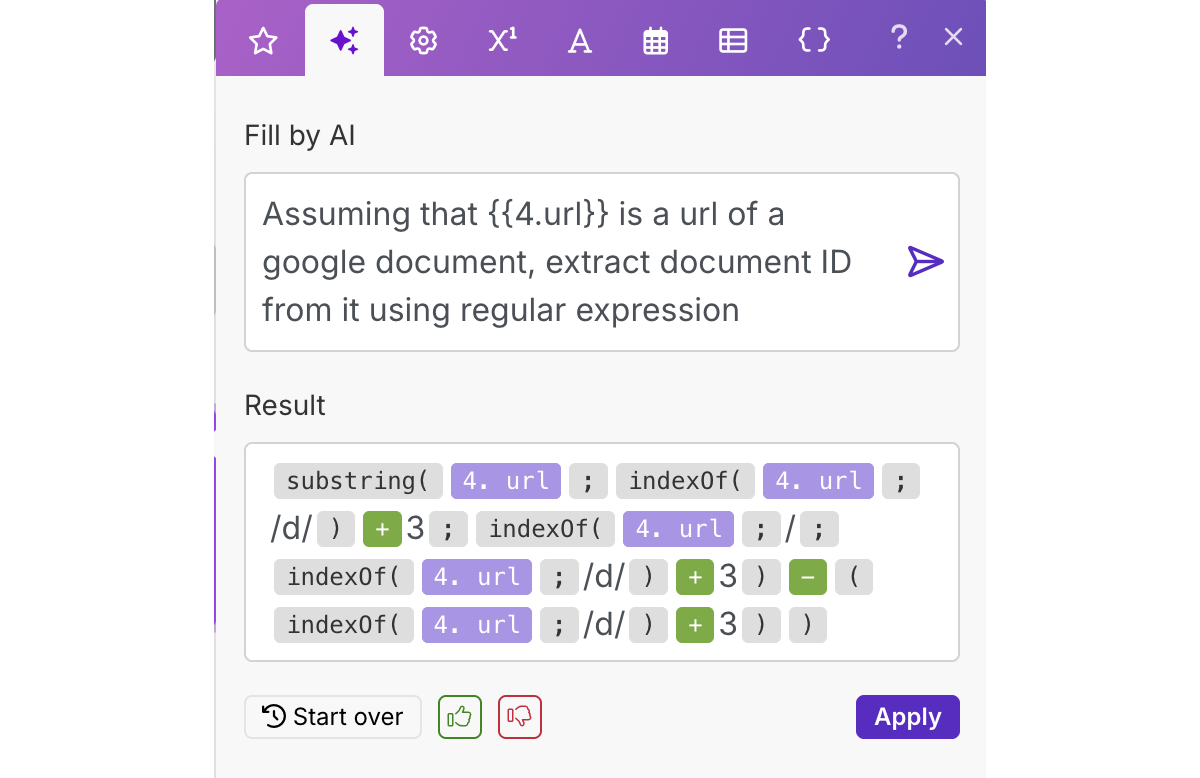
2.9. Транскрибация видео из YouTube
Больше всего времени мне экономят тексты, полученные из видео. На все интересные видео времени не хватит даже теоретически. И даже если я видео послушал сам, самостоятельно писать его саммари для базы знаний — не вариант.
Транскрипт и саммари youtube-видео сейчас можно быстро получать в двух чат-ботах: aistudio.google.com (бесплатно) и perplexity.ai (с подпиской Pro). Но как это сделать в полностью автоматическом режиме?
Сам YouTube через Google Data API может отдать субтитры лишь тех видео, которые принадлежат вам. Раньше субтитры могли выгружать сервисы типа apify.com и 0codekit.com, которые извлекают из кода YouTube-страницы временный URL для загрузки субтитров, но с недавнего времени YouTube заблокировал их. То же самое можно было бы сделать двумя HTTP-запросами в самом Make.com, но и он заблокирован.
Поэтому я воспользовался менее известным сервисом Supadata.ai, который дает бесплатно 100 запросов в месяц. Он принимает URL видео и возвращает дословный транскрипт видео, без тайм-кодов.

Кстати, если вам нужны какие-то еще виды веб-страниц, которые не были описаны в предыдущем разделе, то для их парсинга тоже можете попробовать воспользоваться Supadata (лучше в отдельном аккаунте, так как лимит «100 в месяц» касается также и веб-страниц).
На этом заканчивается разбор базового no-code сценария пополнения личной базы знаний. С учетом этого конкретного сценария осталось понять ответ на общий вопрос — а стоит ли все-таки связываться с no-code для более сложных задач?
3. Ограничения и преимущества no-code инструментов
3.1. Трудоемкая поддержка 😢
Некоторые говорят, что no-code сценарии удобнее поддерживать, чем программный код, но думаю, любой программист сочтет это утверждение неверным.
Хотя в ноу-код платформах встроены возможности для отладки, в ноу-коде сложнее:
- тестировать (в частности, невозможны нормальные
юнит-тесты),
- искать в большом сценарии нужное место для внесения
изменений (тогда как поиск — лучший друг программиста),
- версионировать (впрочем, вы можете эмулировать создание версии, если экспортируете ваш сценарий в текстовый формат JSON — в Make это называется Blueprint)
Более того, проблемы с поддержкой no-code workflows будут возникать, если не принять специальных мер для устранения дублирующих последовательностей блоков. Иначе внесение изменений становится проблемой. Например, два почти одинаковых блока поправили, а про третий забыли — получается дефект, который сложно обнаружить своевременно.
Чтобы избегать дублей, в n8n есть sub-workflows, в Zapier — sub-zaps, в Make.com — subscenarios:
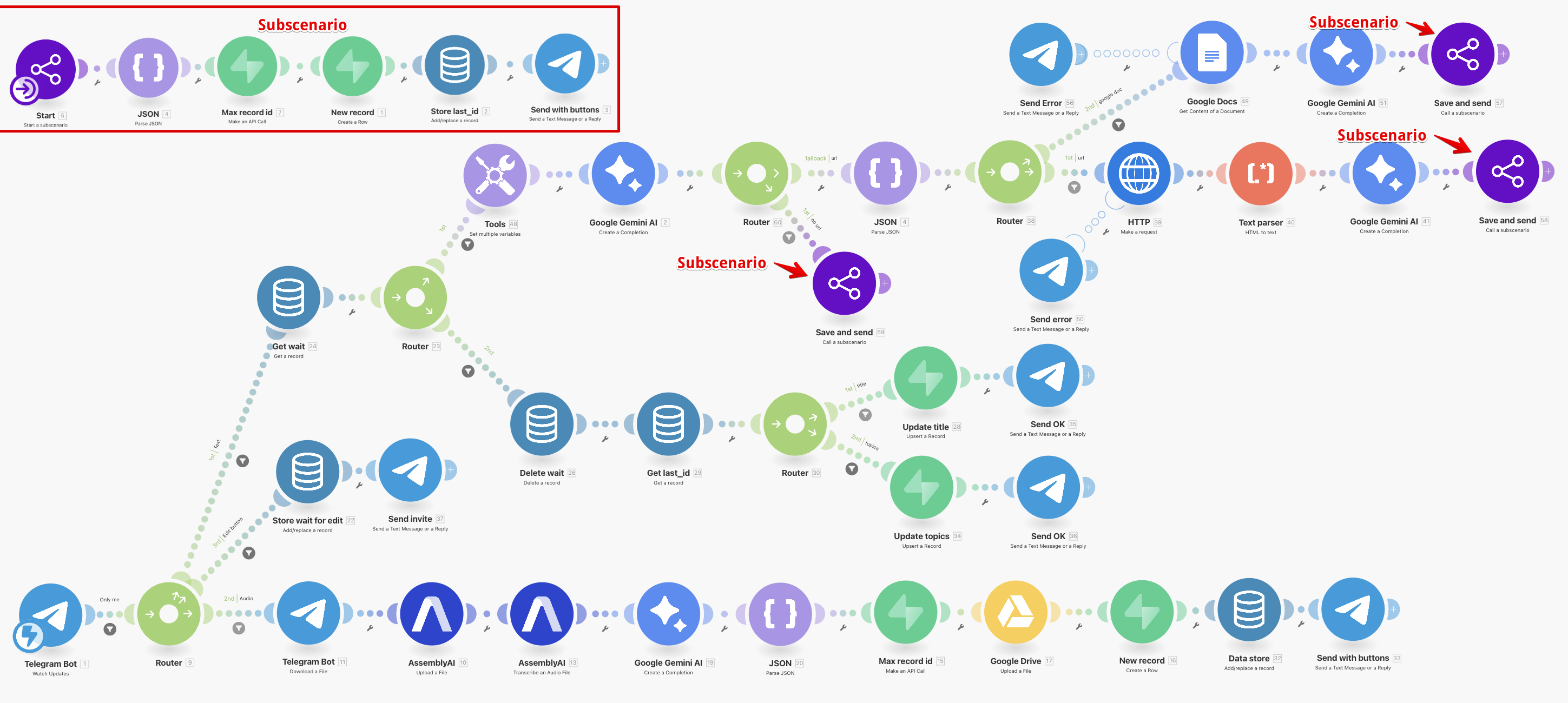
3.2. Быстрая замена реализации 👍
Главное, что мы получаем от no-code — это готовые интеграции с практически любыми системами, преобразующими и хранящими наши данные.
Причем одну систему в no-code сценарии очень просто заменить на другую — например, если прежняя система стала дорогой или нашлась система, дающая лучшую реализацию функционала.
Программные же интеграции, особенно если они сгенерированы AI-агентом, не любят такие замены систем, поэтому в обычных программах они делаются лишь в случае необходимости. В этом случае экспериментировать с разными системами часто — не лучшая идея, даже если код интеграции пишет ИИ. Ведь после каждой замены нужно все перетестировать, поскольку в интеграциях ИИ часто допускает ошибки, в т.ч. из-за несовершенства API-документации.
3.3. Цена 🤔
Помимо простоты/скорости разработки и поддержки, цена — это тоже очень важный аспект сравнения no-code платформ с AI-агентами для программирования («вайб-кодинга»).
По цене продакшен-решений, конечно, программный код выигрывает, поскольку no-code платформы берут деньги, по сути, за каждую операцию. Исключение — открытые платформы с хорошей лицензией — особенно n8n, которую несложно самостоятельно развернуть на некоторых хостингах прямо в панели управления — не имея навыков работы в командной строке Linux.
Однако даже коммерческая no-code-платформа может быть дешевле обычной разработки а) для MVP б) для личного использования на постоянной основе. В статье описан как раз случай (б) — собранный персональный сценарий работает полностью бесплатно.
- Бесплатного тарифа Make.com (1000 операций) хватит
на 50-70 записей базы знаний в месяц. Это главное ограничение, и если
оно вас лимитирует — стоит сразу подумать об n8n на своем
хостинге.
- Сама база — Supabase, бесплатных 500Мб хватит
надолго (а файлы, если они нужны, лучше хранить в облаке типа Google
Drive). Кстати, инструменты вайб-кодинга типа Lovable легко сделают вам
нужный UI к Supabase, но это отдельная тема.
- В Google модели Gemini Flash доступны
бесплатно.
- В транскрибаторе AssemblyAI бесплатных 416 часов
хватит на ~год регулярных голосовых заметок, потом нужно менять
аккаунт.
- В youtube-транскрибаторе Supadata — 100 видео в месяц, в веб-скрейпере ScrapeNinja — 50 CSR-страниц в месяц (для обычных веб-страниц это не нужно).
4. Что дальше
Когда вы пройдете по моей инструкции, у вас получится то, что принято называть AI workflow automation.
Это отнюдь не AI-агент, поскольку ИИ здесь используется только для преобразования данных на отдельных шагах, а логика в целом фиксирована визуальной схемой шагов. То есть, ИИ здесь не принимает решений о том, какие задачи в какой последовательности нужно выполнять для достижения цели. Это отличие AI agents vs. AI workflows изложено в статье Building Effective Agents от компании Anthropic (вот ее русский перевод).
Однако простых AI-агентов создавать уже можно и даже нужно — см. ниже.
4.1. Как применить AI no-code к задачам команды и организации
После того, как вы освоите AI workflows на таком персональном сценарии, рекомендую:
- Применить полученные навыки к автоматическому пополнению и наведению
порядка в корпоративной базе знаний, чтобы обеспечить
актуальность и понятность этой базы для всех. В отличие от личных
сценариев, я рекомендую сразу использовать не Make, а n8n на
сервере компании. Причем «наведение порядка» должно быть в
отдельных фоновых пайплайнах, обрабатывающих тот контент, что насобирают
пайплайны пополнения.
- Откуда пополнять базу знаний — вам виднее, но я бы начал с такого
важного источника знаний как корпоративный мессенджер —
хотя бы каналы/чаты с большим числом человек. Выделять оттуда нечто
достойное базы знаний непросто, но оно того стоит. Только не забывайте
настроить информирование людей о добавлении записи в базу знаний;
желательно с возможностью участникам чата тут же исправить параметры
записи или удалить ее.
- После реализации подобных сценариев обратите внимание на
создание своих AI-агентов: в n8n это описано здесь (в Make — здесь). Это нечто среднее
между теми AI-блоками, которые вы делали до сих пор в n8n/Make, и
полноценными универсальными агентами типа Manus, Genspark или
опенсорсного II-Agent. То
есть, агент должен отвечать за часть логики работы сценария, а не быть
лишь звеном заранее придуманной логики.
- Лишь после того, как в базе знаний с помощью ИИ наведен хотя бы
минимальный порядок, стоит делать чат-бот или иной инструмент,
помогающий сотрудникам общаться с этой базой знаний.
Иначе результаты такого общения рискуют быть плачевными — зачастую хуже,
чем у обычного полнотекстового поиска по базе.
- Далее стоит подключить транскрипты созвонов как
триггер для запуска таких сценариев как: выявление проблем на встречах
по критериям, создание элементов бэклога или авто-отчетов, уведомление о
дисфункциях для конкретных ролей и т.п. Подробнее
об этих сценариях
- Ну, а дальше все ограничено лишь вашей фантазией — ИИ может консультировать сотрудников при обнаружении несоответствий с политиками компании, фасилитировать коммуникации в чатах, выступать в них от вашего имени и т.д. Но стоит сказать, что пока лишь немногие компании дошли до уровня, описанного в пункте 5. Так что этот пункт 6 — пока лишь выгодная перспектива, а не текущая реальность.
4.2. Что стоит доработать для личной базы знаний
Как минимум, в рассмотренном сценарии стоит реализовать две фичи:
- Редактирование только что созданной записи, показанное на общей
блок-схеме в разделе 2. Имеет смысл редактировать категории и заголовок
записи.
- «Самообучение» категоризатора и составителя заголовков (иначе предсказуемость результатов будет невысокой, и часто придется править вручную). Это можно реализовать, помечая некоторые записи образцовыми как раз в процессе редактирования.
Отдельная тема — это семантический поиск и ответы ИИ по базе знаний.
- В компаниях это реализуется обычно через RAG (Retrieval-Augmented
Generation). Это когда накопленные знания преобразуются в векторное
представление (эмбеддинги), а затем происходит поиск записей в базе
знаний, которые в этом векторном представлении наиболее близки входящему
запросу.
- Впрочем, небольшая персональная база знаний полностью помещается в
контекст Gemini 2.0 Flash с большим запасом (там 1 миллион
токенов).
- Не зря же каждый источник при пополнении базы данных саммаризировался — это обеспечивает возможность обойтись без RAG, а в случае RAG — существенно уменьшить вероятность нахождения нерелеватной информации в длинных текстах.
Ну, а в перспективе можно настроить, чтобы Telegram-бот копил гораздо больше контекста из любых чатов — прежде всего, ваши слова в чатах, а не чужие. И чтобы на основе этого контекста бот отвечал за вас на заданные вам вопросы, если вы вовремя не ответили (Telegram Premium это позволяет).
Этот непростой и далеко не бесплатный инструмент уже выходит за рамки персональной базы знаний (PKM, Second Brain). Он относится скорее к концепции Knowledge-Based Digital Twin. Я его пока не реализовал в no-code, а готовые дорогие инструменты на эту тему мне кажется пока слишком незрелыми.
Продолжение этой темы смотрите в нашем телеграм-канале. А еще там в канале мы делимся советами о применении ИИ и объясняем новости мира ИИ с точки зрения менеджмента. Присоединяйтесь!
