Вы хотели бы понять возможности no-code, прежде чем внедрять AI-автоматизацию в своей команде или компании? Тогда попробуйте сначала сделать no-code автоматизацию для себя лично. Достоинства и недостатки no-code лучше прочувствовать самостоятельно, чем посмотреть десяток статей или видео на эту тему.
Персональные сценарии автоматизации (pipeline) обычно проще рабочих пайплайнов — с персональных проще начать. А главное — вы не только поймете преимущества и ограничения ноу-кода, но и получите полезный именно для вас AI-инструмент, который сможете затем развивать под свои потребности и дальше.
В этой и следующей статьях вы найдете пошаговую инструкцию о том, как автоматизировать пополнение личной базы знаний:
- Добавлять в базу свои голосовые и текстовые заметки, чужие посты,
ссылки на интересные статьи и ресурсы.
- С помощью ИИ снабжать каждую запись в базе заголовком и краткой аннотацией (summary), а также категориями (будь то удобные вам тематические категории, части вашей профессиональной/личной жизни или названия ваших проектов)
В этой статье разберем только транскрибацию и ИИ-обработку голосовых заметок. Если вы на этом остановитесь — у вас все равно останется законченная автоматизация для этой цели. Это будет не «единая база знаний», но все равно полезно: избавит вас от ручной работы по структурированию заметок и радикально облегчит их поиск.
Введение
В области No-code почти нет теории и общих рецептов. Поэтому я опишу мой практический опыт — на основе моих личных критериев полезности такой автоматизации. Основных критериев у меня было два:
- Бесплатность всех инструментов (подробнее о
вытекающих из этого ограничениях см. во второй части статьи).
- Telegram-бот как единый инструмент пополнения базы. Для меня он самый удобный, так как основную информацию я черпаю из telegram-каналов и чатов, а остальное можно пошарить боту, например, через функцию «Поделиться / Telegram» в любых мобильных приложениях.
Если эти слова вас не устрашили, можете еще оценить полезность no-code для вас по вот этой верхнеуровневой схеме моей автоматизации:
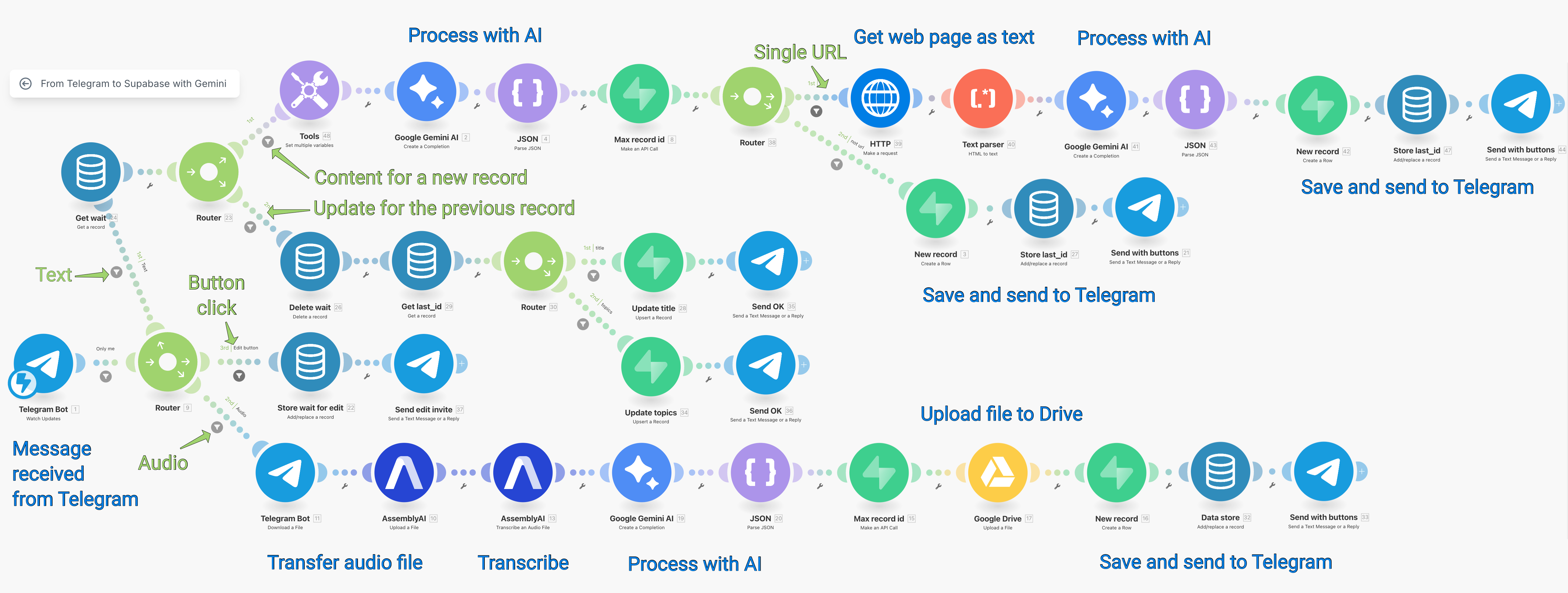
Эту схему из no-code платформы Make.com я дальше объясню детальнее, но если вам она непонятна в целом — возможно, вам не стоит пробовать Make.
И это требование технической грамотности касается любых no-code инструментов — не только Make. «Без кода» отнюдь не означает «без логики» или «для начинающих пользователей, никогда не менявших настройки облачных приложений».
Прежде чем отвечать на вопрос «КАК построить no-code автоматизацию?» (в разделе 2), давайте ответим на вопрос «ЗАЧЕМ это делать без кода?».
1. Когда нужен no-code?
На самом деле, с появлением ИИ-агентов даже непрограммистам нередко будет проще и быстрее создавать себе инструменты на основе кода. Другими словами, будет проще и быстрее пользоваться такими пишущими код AI-агентами как Replit, v0.dev или Lovable, а отнюдь не визуальными no-code конструкторами типа Make, Zapier или n8n. Уже сейчас нередко получается «проще и быстрее» с кодом.
И действительно, AI-агентам нужны лишь промпты на естественном языке (даже необязательно на английском). А написать промпты большинству пользователей проще, чем аккуратно прописывать логику в no-code системе:
- Чем строить no-code workflow из десятков блоков, проще получить от
AI-агента готовое простое приложение, попробовать его в действии и
несколько раз дать агенту критические замечания, которые он с некоторой
вероятностью успешно исправит. Сейчас это называется вайб-кодингом.
- В частности, в no-code почти всегда бывают нужны технические блоки типа “Сохранить переменную” или “Преобразовать в JSON”, смысл которых понятен лишь людям с техническим образованием или опытом. AI-агенты же лишают нас необходимости разбираться в излишних деталях логики работы приложения.
И почему их популярность выросла с появлением ИИ?
1.1. Когда у вас задачи автоматизации, а не UI
Во-первых, есть задачи, где ключевые элементы логики приложения отнюдь не являются «излишними деталями» — они должны быть понятны вам как заказчику. В таких задачах вам как заказчику хотелось бы видеть блок-схему того, что происходит. И именно вам как заказчику проще внести изменения в no-code блок-схему или в ее элементы, чем объяснять эти изменения программисту или AI-агенту.
Сказанное касается, прежде всего, операций передачи данных между разными системами — в нашем случае между мессенджером, транскрибатором, базой данных и облачным диском. А также операций преобразования данных — например, саммаризации текстов или преобразования файлов в другой формат. Операции преобразования стали на порядок более мощными и потому более востребованными с появлением генеративного искусственного интеллекта, и это отчасти обусловило рост популярности no-code за последние два года.
Однако большинство задач в мире пока еще требует пользовательский интерфейс — например, для удобного редактирования и визуализации информации. И вот как раз UI-задачи плохо решаются с no-code.
Конечно, для UI есть специализированные no-code системы, а не Make или n8n. Например, Bubble.io или Flutterflow. Однако они так и не стали конкурентами традиционной разработке приложений, и даже появление мощного ИИ на их популярность повлияло скорее отрицательно.
1.2. Когда вы любите детали и/или имеете мало опыта
Во-вторых, чтобы получить достойный результат от AI-агента, нужно понимать архитектуру/дизайн приложений и знать соответствующие слова.
Как следствие, no-code платформы хороши для тех людей, кто готов вникать в детали; при этом они могут не иметь высокоуровневого понимания. Я бы даже сказал, что выбор “code или no code” зависит в большей степени от доминирующего психотипа человека (либо внимание к деталям, либо стратегическое мышление), чем от наличия/отсутствия у него опыта в индустрии разработки программного обеспечения.
Хотя чем больше такого опыта — тем меньше нужен классический no-code и тем лучше получается писать промпты для агентов. Лично у меня не так много опыта в индустрии, при этом я люблю детали, так что AI-агенты меня меньше возбуждают, чем AI-копилоты и no-code. У вас может быть наоборот.
1.3. Когда вы готовы к ИИ-генерации no-code
В-третьих, no-code сценарии, несмотря на свою ви��уализацию в виде блок-схемы, неплохо представляются также в текстовом формате. Например, в Make для этого есть операция Export blueprint.
Более того, если вы попросите у коллеги или знакомого его сценарий, с помощью ИИ вы легко поймете сценарий и сможете адаптировать его под себя. Например, вот что объяснил ChatGPT про мой сценарий с личной базой знаний.

Ну, а чтобы избавиться от таких ручных операций как «экспортировать сценарий» / «проанализировать/улучшить с ИИ» / «импортировать обратно», уже начали появляться удобные продукты. Например, n8nchat.com, где AI помогает быстро строить/улучшать no-code прямо в браузере. Однако эти продукты пока «сырые», т.е. нужно быть готовыми с ними экспериментировать и исправлять их ошибки.
Впрочем, и классические ИИ-чатботы типа ChatGPT/Gemini/Perplexity отнюдь не гарантируют отсутствие проблем в сгенерированных сценариях. Например, если вы просто попросите ИИ подключить систему, которой в сценарии пока нет, с большой вероятностью будут галлюцинации в деталях. Нужно, как минимум, давать ИИ ссылку на информацию по этой системе (лучше всего на страницу типа https://www.make.com/en/integrations/slack).
Таким образом, реализация задачи через no-coding вместо AI-coding:
- зависит от самой задачи (например, no-code UI лучше избегать);
- зависит от вашего характера (например, любители копаться в деталях могут впадать в ступор от необходимости писать промпты, но легко строить сложные no-code сценарии).
А если и задача комплексная, и сами вы не имеете подобных преференций, то вам будет удобно строить и улучшать no-code с помощью ИИ. К тому же UI можно реализовать в коде, а внутреннюю логику системы — без кода. Т.е. это не совсем альтернативы.
2. Сценарий с голосовым сообщением в Telegram: пошаговая инструкция
2.1. Начало и конец цепочки автоматизации
Напомню, мы хотим обрабатывать сообщения из Telegram.
Поэтому сначала создаем Telegram-бот в t.me/BotFather: пишем /newbot, вводим имя бота (например, «Моя база») и его уникальный username, заканчивающийся словом bot. BotFather выдаст «токен», который нужен далее.
Затем регистрируемся в Make.com (именно на этапе регистрации живущим в России потребуется VPN, но потом можно его выключить).
Быстрее всего создать свой первый сценарий в Make из готового шаблона: вот список шаблонов, содержащих Telegram. Рекомендую взять этот шаблон, который записывает сообщения Telegram в Google Sheet. Именно Google Sheet начинающим удобно использовать в качестве бесплатной «базы данных.
После нажатия на кнопку «Create scenario from this template» (или после создания пустого сценария и добавления к нему блока Telegram / Watch Updates) нужно 3 раза кликнуть (см. скриншот) и далее ввести полученный от BotFather токен.
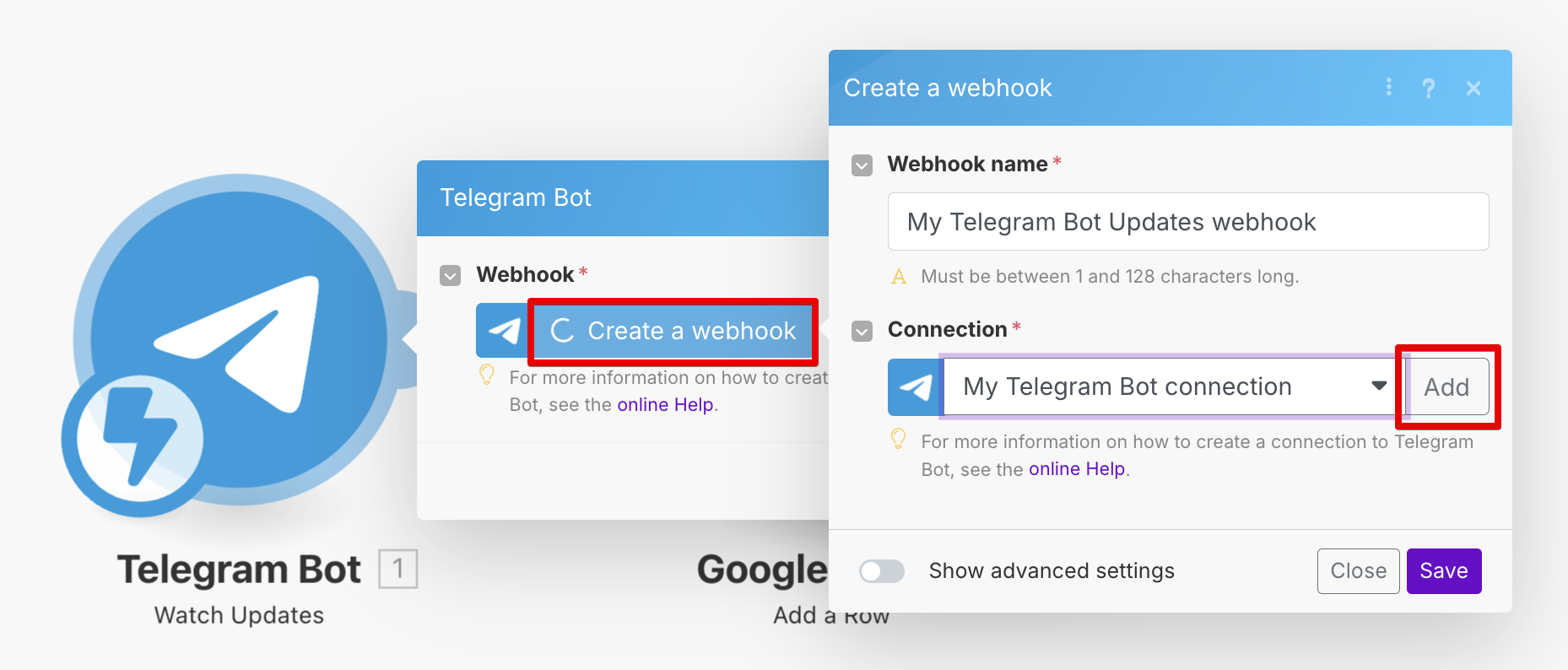
Подобные поля Connection с кнопкой Add вы увидите каждый раз, когда будете добавлять в свой сценарий новые блоки (блоки в Make называются modules).
Для подключения к Google потребуется кликнуть 6 раз; два первых клика и предпоследний клик выделены красным:
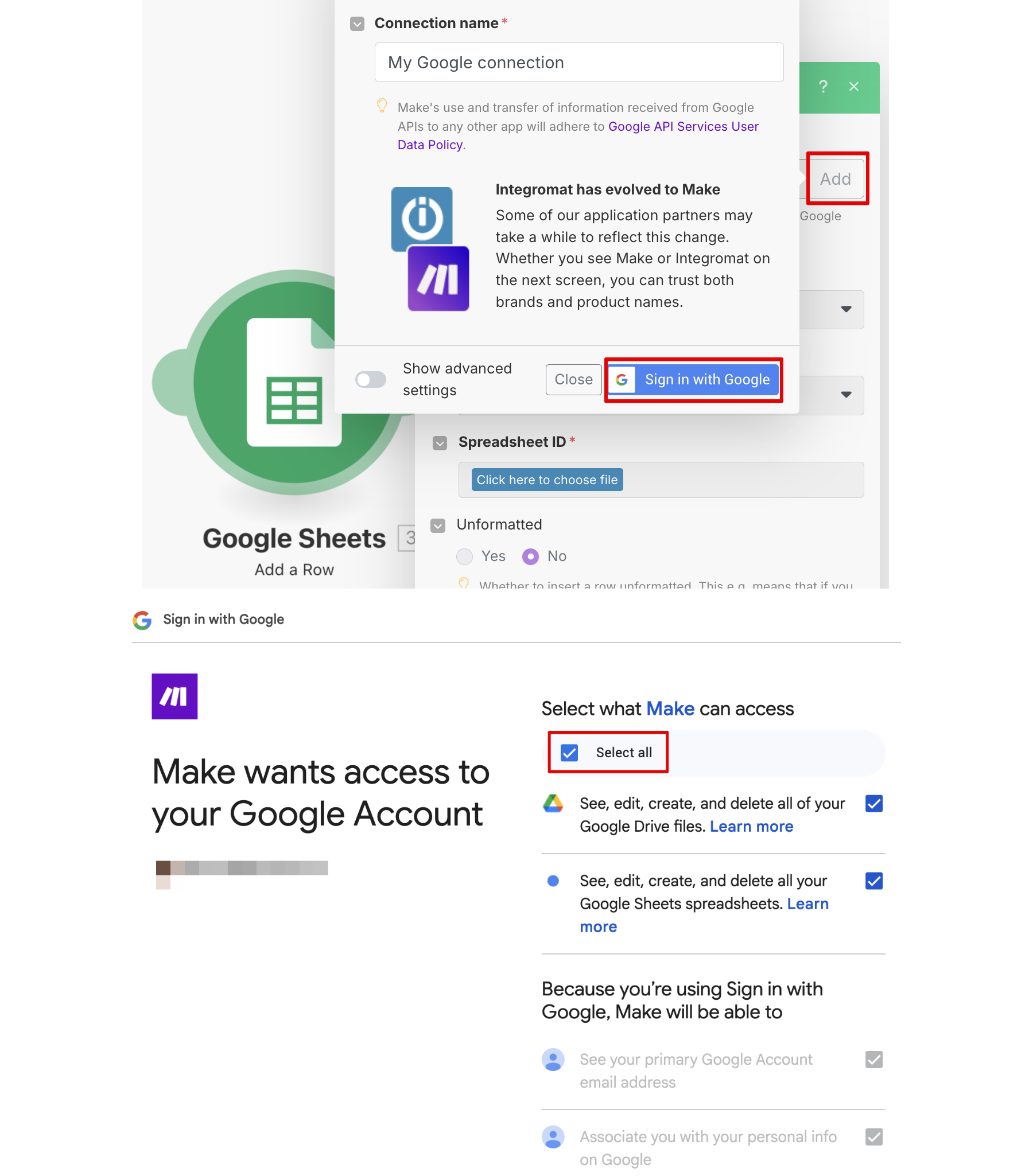
В случае Google Sheets потребуется еще указать еще конкретный spreadsheet, куда будут сохраняться ваши данные (только заранее его создайте, чтобы его можно было выбрать в поле Spreadsheet ID). На скриншоте также показано сиреневое меню Make, где можно найти разные функции, в данном случае — для сохранения даты/времени в нужном формате:
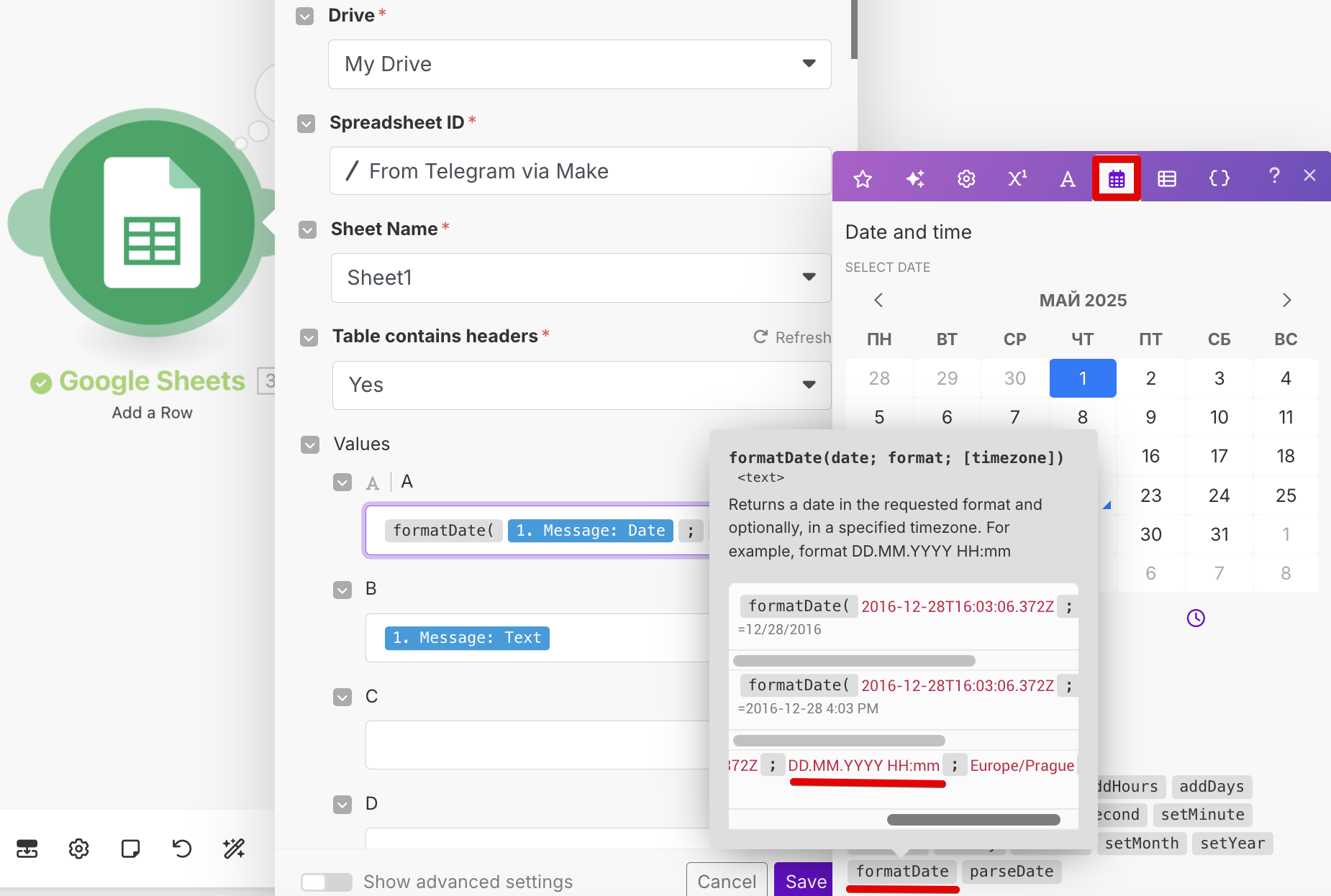
Если же вы решили последовать моему примеру и хранить знания в реляционной базе Supabase, то здесь иные настройки подключания — Project ID и API Key. На скриншоте указано, где их взять после регистрации в Supabase:
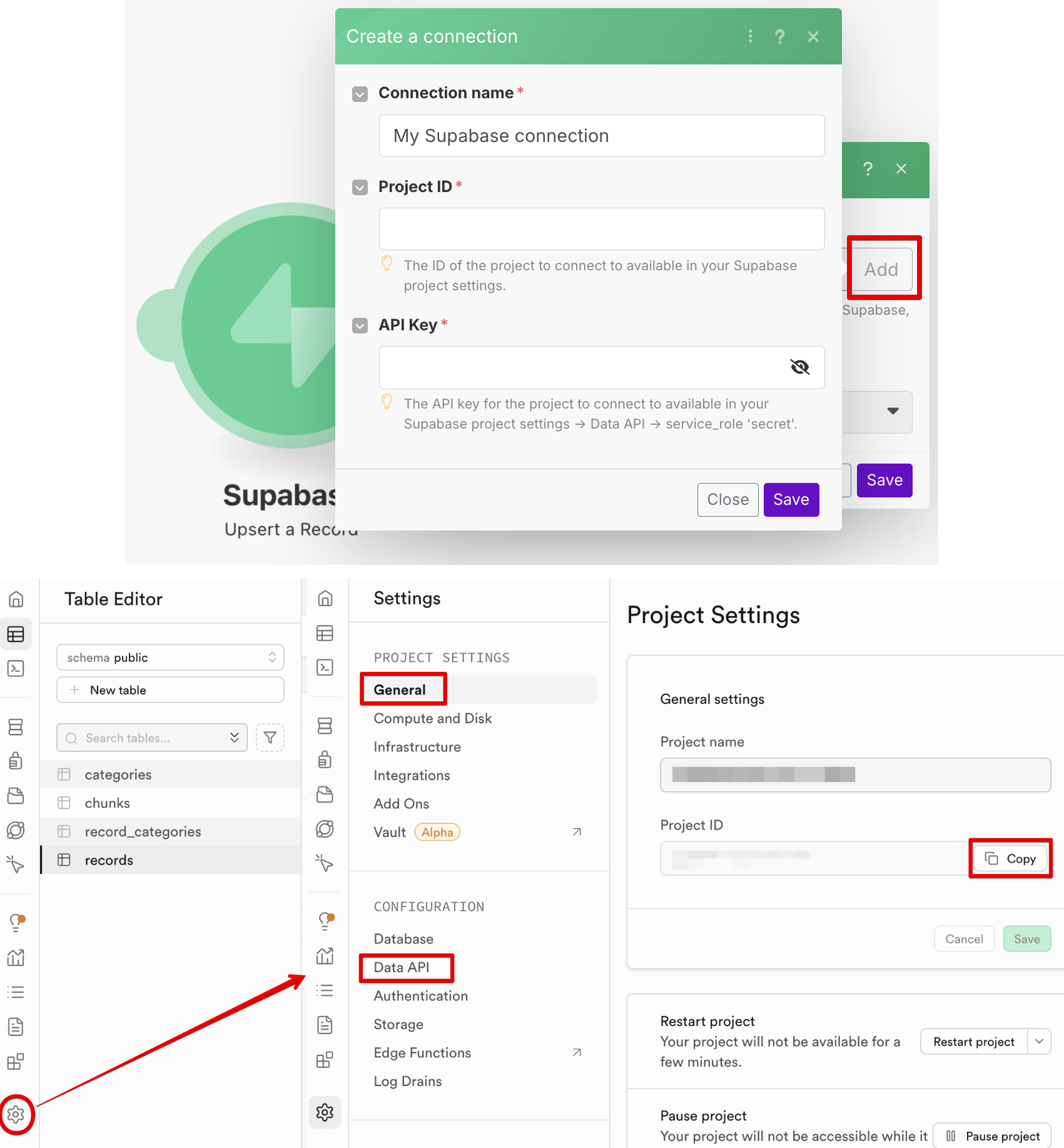
Реляционную базу имеет смысл создать, если вы хотите просто повторить мой сценарий с Supabase по инструкции. Но если вы ранее не работали с РБД, лучше все-таки Google Sheet.
Последним элементом цепочки автоматизации в идеале должно быть не сохранение, а отправка ответного сообщения в Telegram:
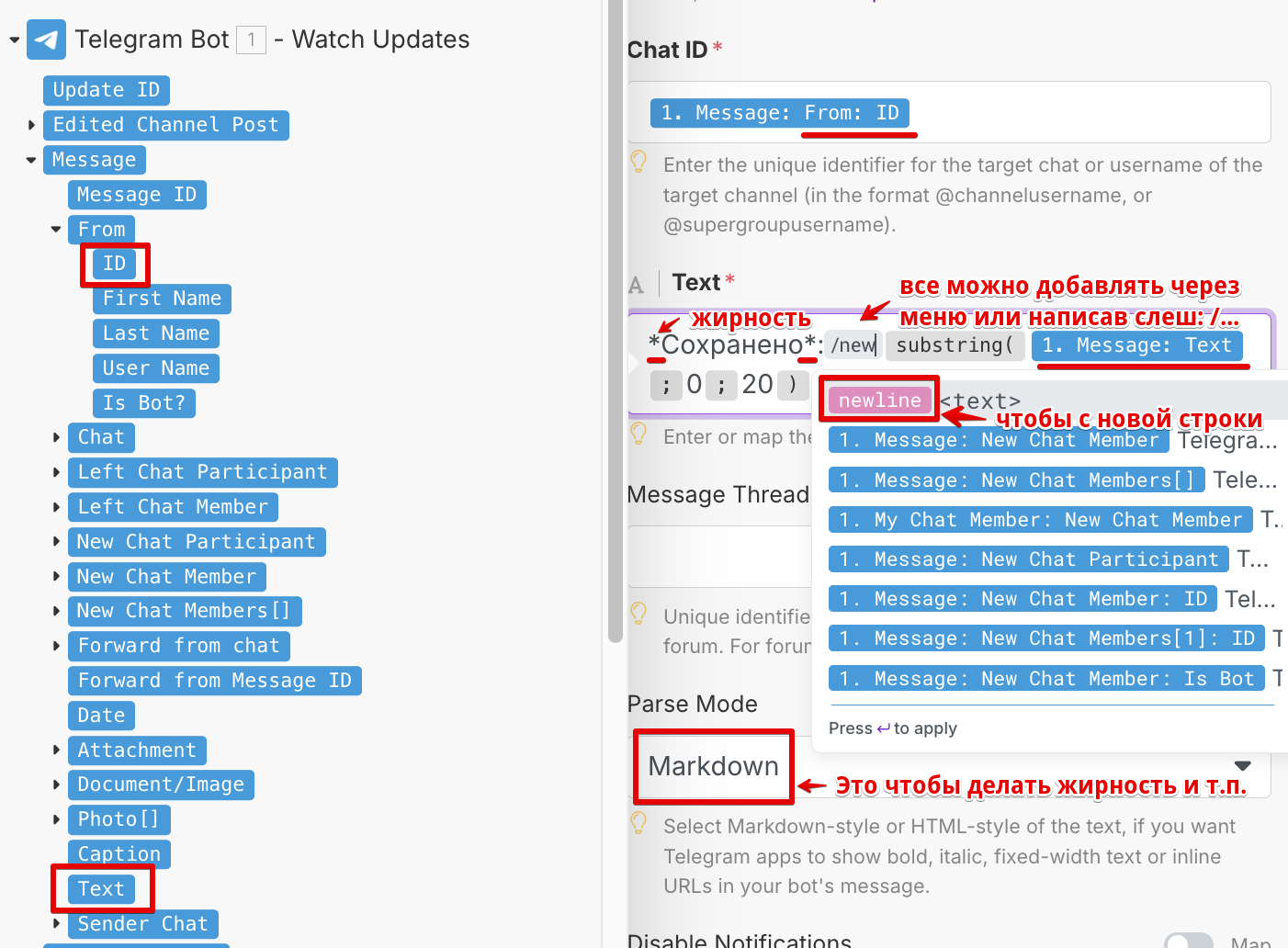
На этом этапе уже можно попробовать применить специальные функции и иные спецсимволы Make — как на скриншоте применена функция substring и константа newline.
2.2. Тестовый запуск
После того, как у вас в сценарии появилось 3 блока Telegram Bot (Watch Updates) ➔ Сохранение ➔ Telegram Bot (Send a Text Message), пора все протестировать!
Для этого в Make нажмите внизу Run once, а затем напишите боту любое сообщение, оно сохранится в базу или Google Sheet, а вы получите ответ в Telegram:
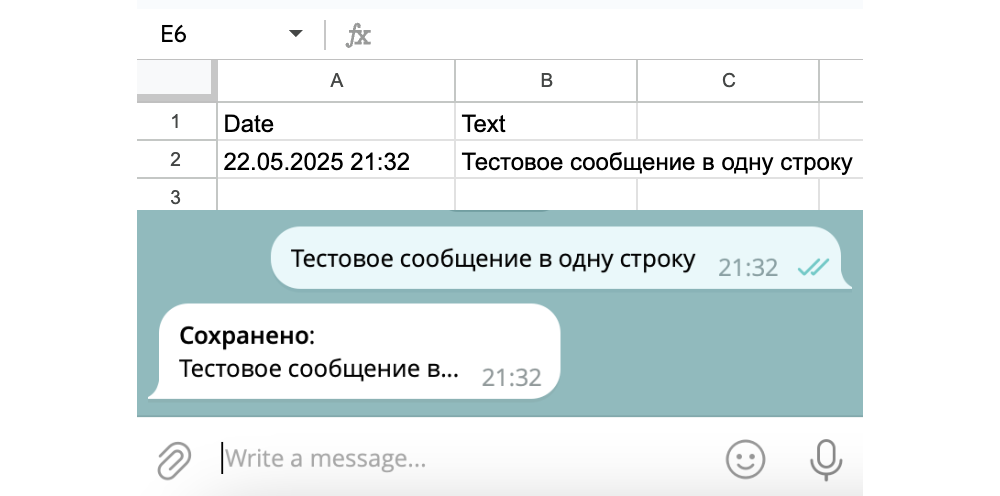
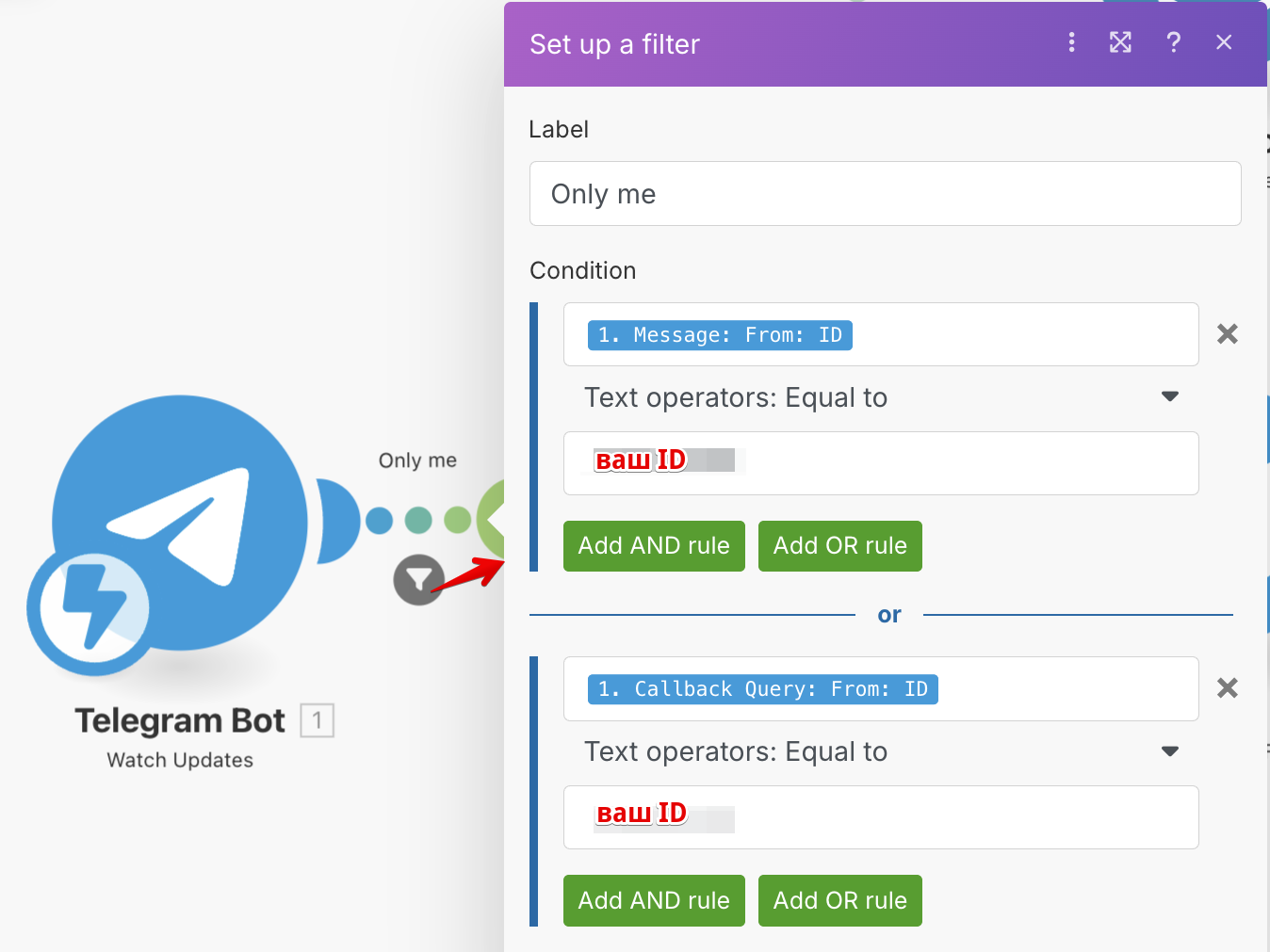
Этот тест не только придаст вам уверенность в своих силах, но и загрузит в Make данные из Telegram, полезные для дальнейшей доработки сценария. На скриншоте видно, в частности, где находится ваш идентификатор юзера Telegram, по которому стоит фильтровать входящие сообщения:
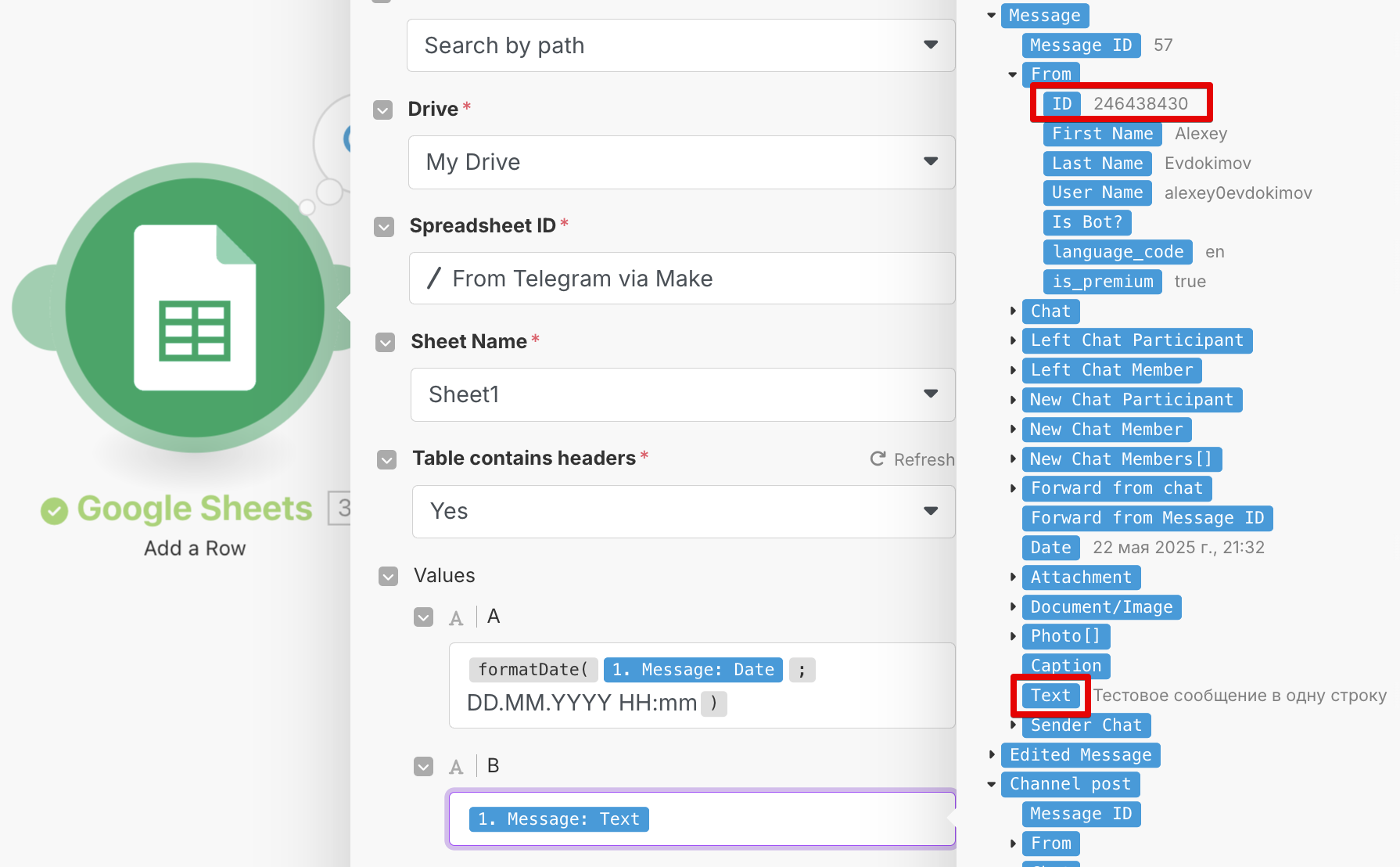
Такой фильтр по условию на Message: From: ID проверит, что в бот пишете именно вы. Мало ли кто может найти ваш бот в телеграме и засорить вам базу.
2.3. Транскрибация голосового сообщения
Пора от тестов переходить к хранению того, что на самом деле вам нужно.
- В этой статье мы обработаем аудиосообщение, в следующей статье —
остальные виды входящей информации.
- В этой статье подключим в сценарий 3 внешних системы (транскрибатор, ИИ, а также облачный диск для сохранения аудио). Но при этом не будет никакой сложной логики — будет лишь единая последовательность блоков, где разветвление («аудио или текст») есть только в начале.

Какие именно блоки нужно использовать в случае конкретной внешней системы — несложно догадаться, введя в Make название этой системы. Я использовал транскрибатор AssemblyAI (который дает много бесплатных часов); вот какие блоки есть у AssemblyAI. Добавив подходящий по смыслу блок Transcribe an Audio File, увидим, что ему нужен файл, ранее загруженный в Assembly. Поэтому перед этим блоком нужно добавить еще два — скачивание файла из телеграма и его загрузка в Assembly (см. скриншот выше).
Дальше я буду пояснять только самые неочевидные моменты.
- Добавление блока в середину цепочки — через контекстное меню (правая
кнопка мыши), пункт Add a module. Там же уже пора
добавить и Router — в данном случае, это будет
ветвление на 2 цепочки — обработка текста (которая была сделана в тесте)
и обработка аудио.
- После Router необходимо ставить фильтры, нажимая на «пунктирную
линию». Условие фильтра для аудио может выглядеть так:
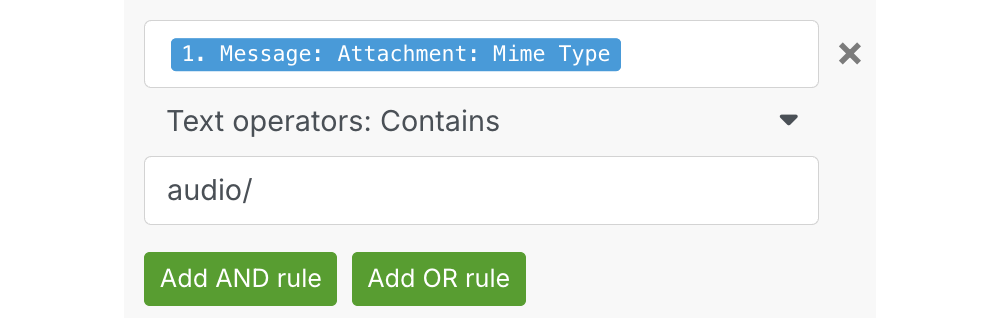
- Неочевидно, откуда брать File ID, который нужен для блока Telegram / Download a File. Чтобы это стало понятно, стоит отправить в бот любое голосовое сообщение и посмотреть, какие поля Telegram имеют непустые значения. Окажется, что можно взять нужный ID двумя способами: Attachment: File ID и voice: file_id. Но вот если вы захотите использовать, например, длительность аудио, то этот атрибут есть только у voice.
2.4. Обработка транскрипта с помощью ИИ
AI — самая интересная и мощная часть автоматизации, но она и самая сложная: надо писать системный промпт. Но начнем с выбора AI-модели.
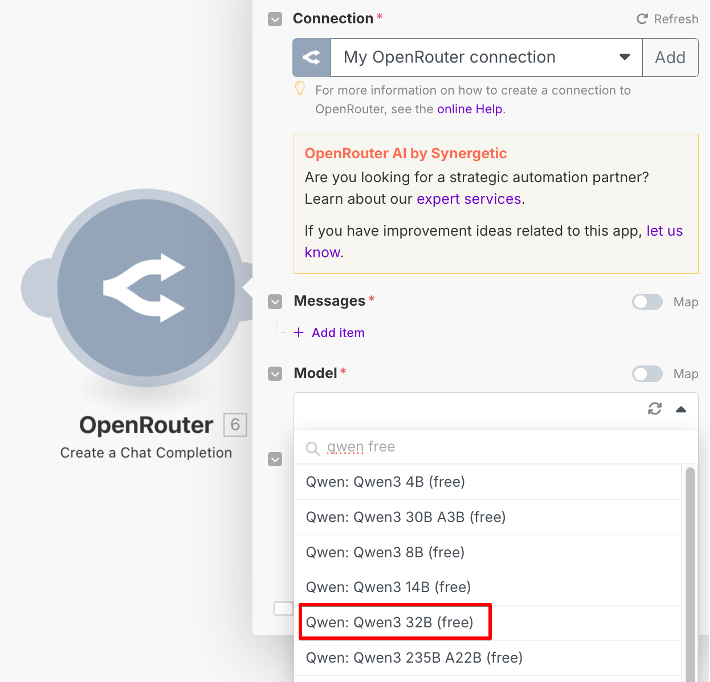
Хотя все провайдеры AI дают конечным пользователя бесплатный доступ к своим чат-ботам, бесплатный доступ к их API получить посложнее. В Make я знаю два способа бесплатно подключить AI — либо модели Gemini Flash (которые сейчас являются одними из лучших), либо некоторые другие модели через сервис-посредник OpenRouter (среди них я рекомендую бесплатные версии хорошей китайской модели Qwen3):
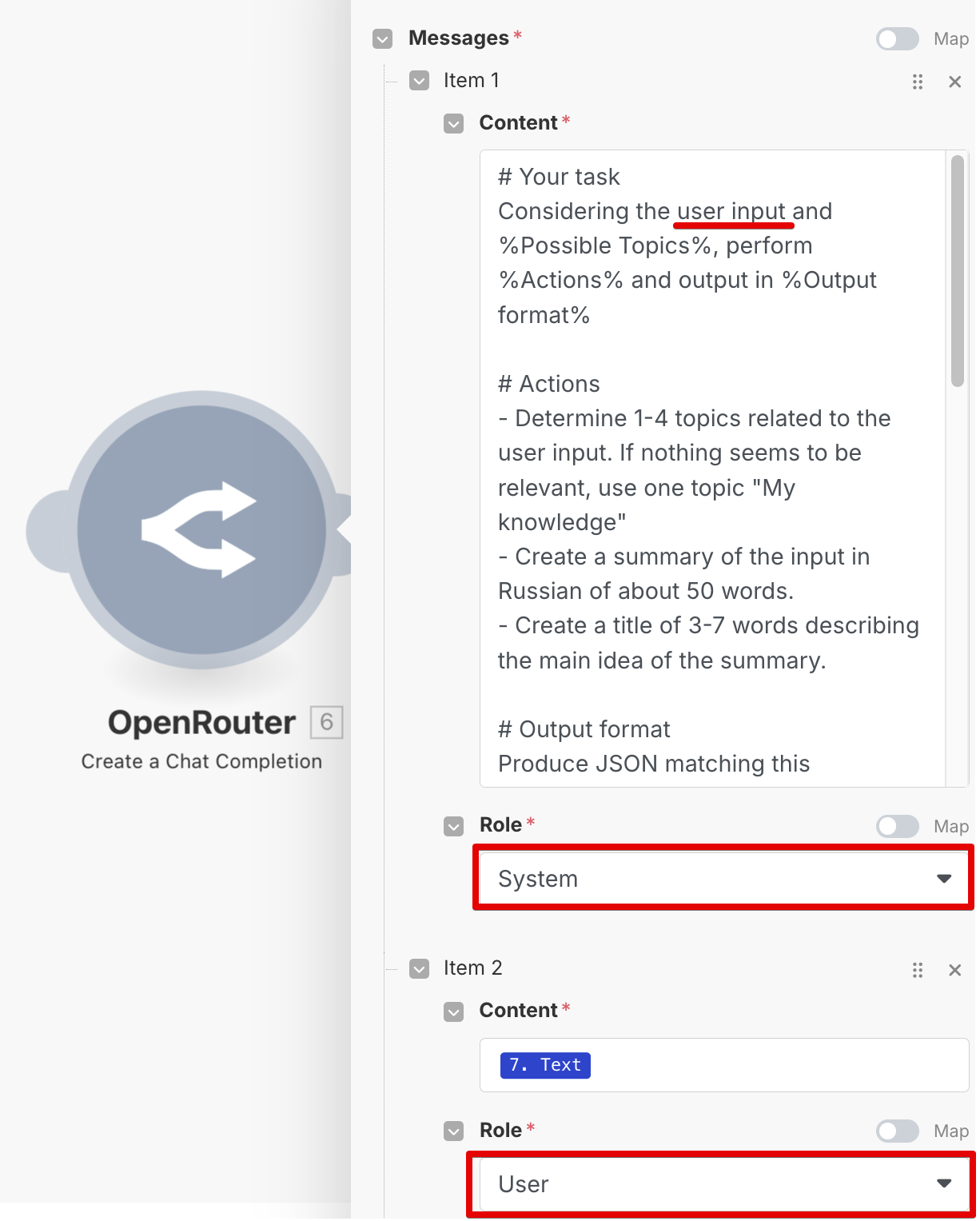
В случае OpenRouter и большинства других AI-провайдеров у вас будет возможность задать отдельно системный промпт. Это необязательно, но я рекомендую именно в нем написать все, что вы хотите сделать (Role: system). И тогда в сообщении с Role: user останется просто добавить Text из результата AssebmlyAI:
В случае Gemini системный промпт отдельно не задается, но это не проблема: просто добавьте в конце промпта заголовок # Input и под ним вставьте тот же атрибут Text из AssembyAI.
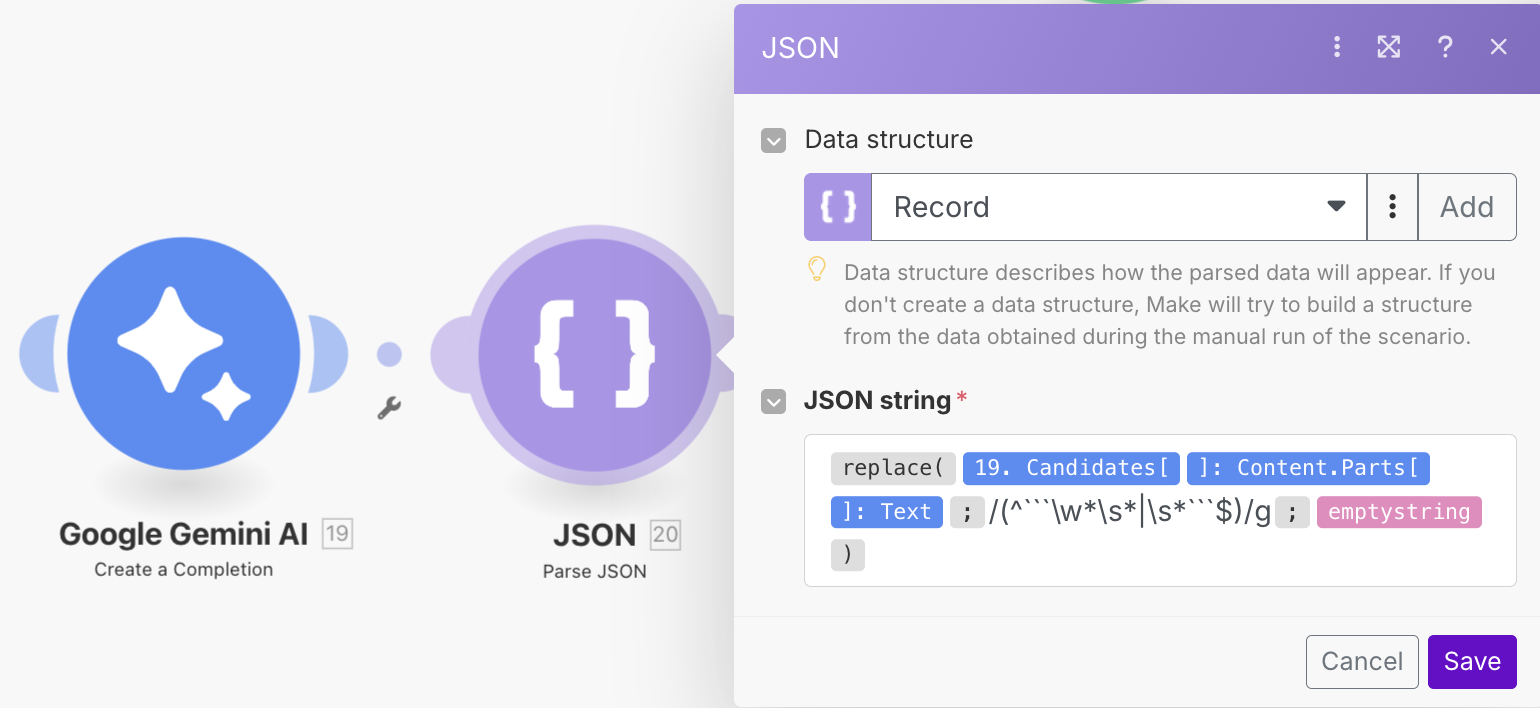
Важно учесть, что большинство моделей выдает не только JSON, но и его обрамление — начиная с символов \`\`\`json — даже если в промпте написать инструкцию типа “Do NOT include \`\`\`”. Исключение — если вы используете платную интеграцию с ChatGPT, где есть блок Transform Text to Structured Data как раз для этой цели. Но надежнее сделать очистку от лишних символов функцией replace внутри блока Parse JSON:
2.5. Сохранение в базу и в Google Drive
В моей версии сценария окончание цепочки обработки аудио выглядит так:

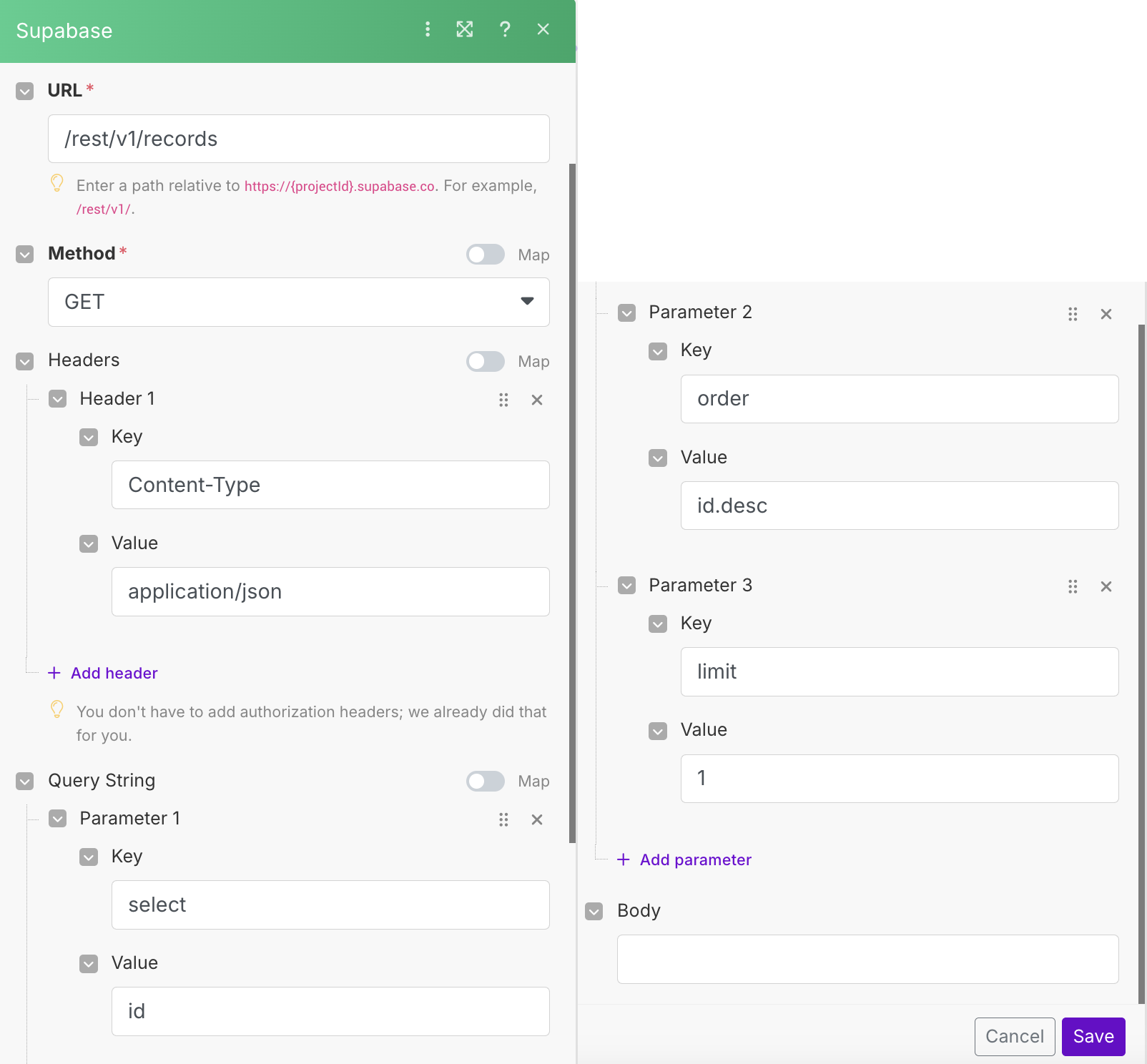
После получения от ИИ JSON с параметрами заметки идут такие блоки:
Я его реализовал через API Call, поскольку готовый блок для агрегирующего запроса к Supabase в Make отсутствует, а применение для этой цели блока Get Rows Count, который мог бы выдавать аналогичное число, по сути, запретило бы мне удалять записи в таблице.
В случае Google Sheet, в отличие от реляционной базы данных, идентификатор записи смысла не имеет, что упрощает эту автоматизацию (но затрудняет последующее редактирование через телеграм).
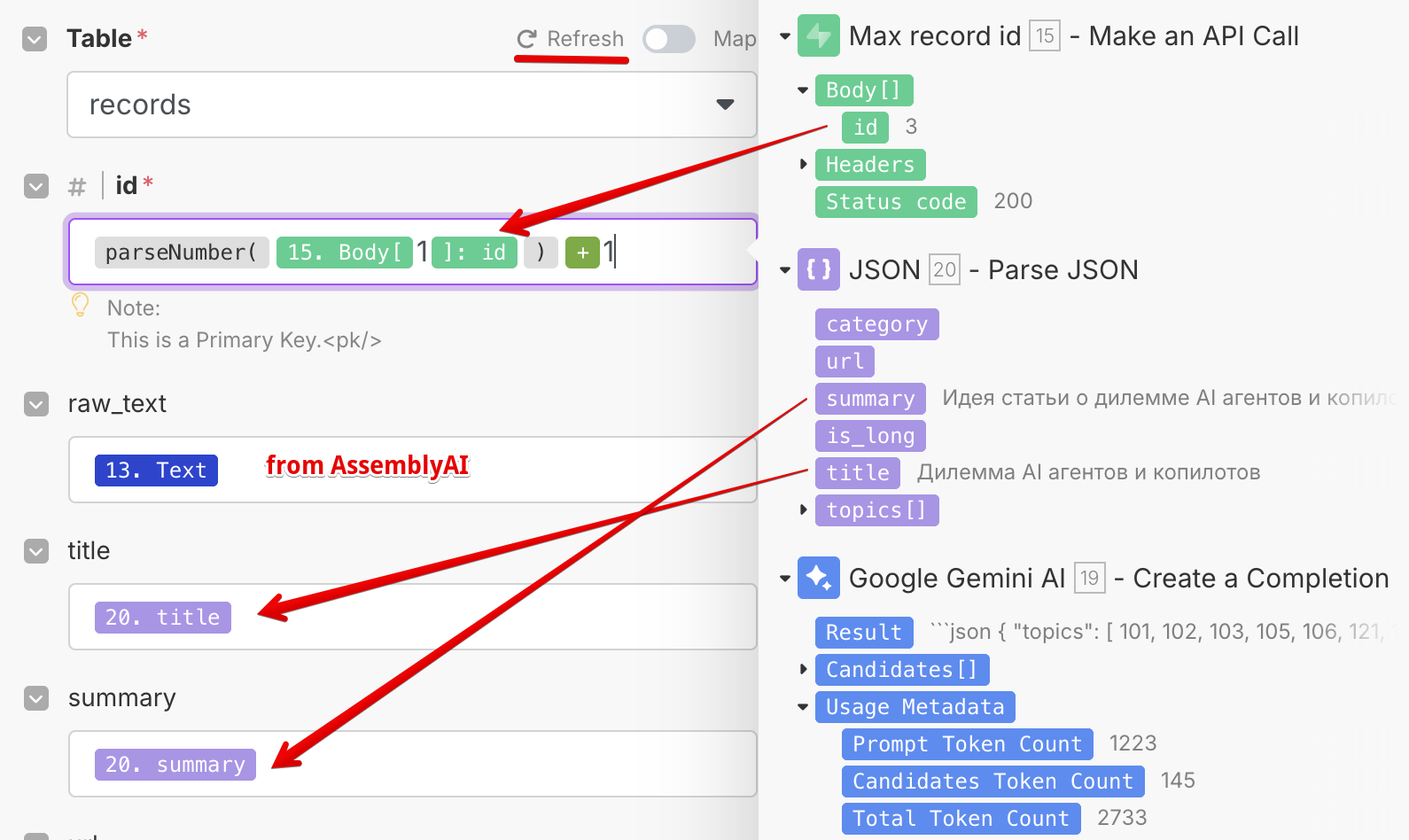
На этом этапе таблица (в моем случае она называется records) должна быть уже создана в Supabase. А если по ходу дела вы решили добавить в нее какой-то столбец, то можно нажать на Refresh, чтобы обновить набор столбцов в редакторе блока New record.
Так что сначала подумайте — а нужно ли вам сохранять файлы, и если да, то сохранять ли в Google Drive. Другие облачные диски, если вы ими пользуетесь, подключить чуть попроще. Можно хранить файлы и в Supabase (Buckets), но бесплатно лишь до 1 Gb (тогда как в Google Drive — 15 Gb).
Более того, в окне подключения Google в Make указана неверная ссылка на документацию о том, что нужно сделать:
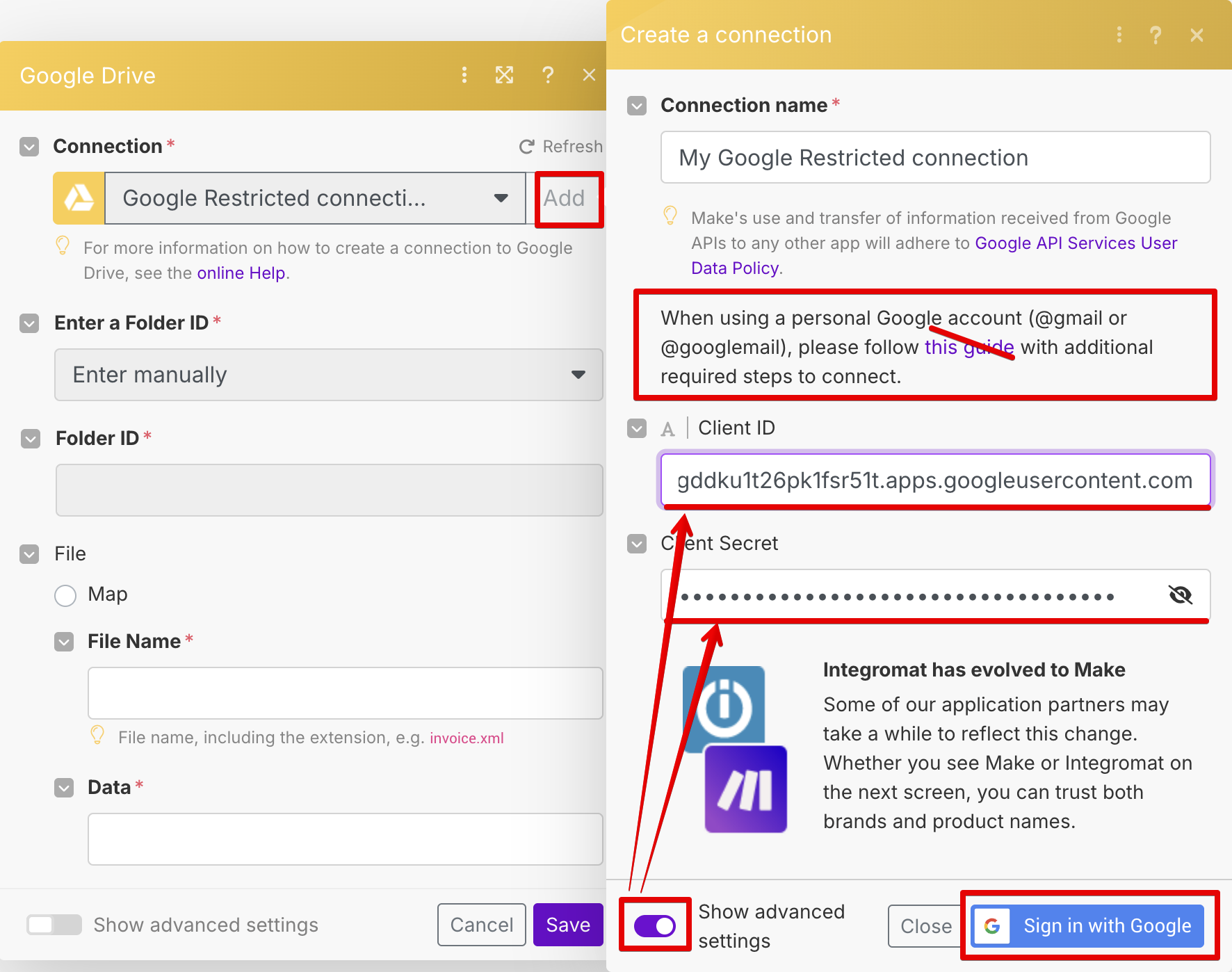
Верная ссылка про Google Drive вот, но нужные действия описаны не для Drive, а для Gmail, так что нужно немного думать, чтобы воспользоваться этой их инструкцией применительно к Drive. Чтобы вам было легче, кратко перечисляю все описанные в инструкции действия в Google Cloud:
- Создать проект, если еще не создан. Возможно, придется указать
страну, отличную от Russia.
- Нажать здесь на
+ Enabled APIs, выбрать Google Drive API и нажать
Enable.
- После этого вам предложат сначала указать email и название
приложения (назвать его можно “Make”), затем нужно выбрать
External Audience.
- После создания приложения вам предложат сконфигурировать
OAuth consent screen, нужно выбрать Web application и
затем добавить в Authorized redirect URIs следующий
url: https://www.integromat.com/oauth/cb/google-restricted
- Тогда вам наконец создадут Client ID и
Client secret; если вы их потеряете — всегда можно
будет найти здесь.
- В соседнем разделе Audience нужно нажать Publish (там будут слова про верификацию приложения гуглом, но она не нужна).
После этого можно прописывать в Make выданные Client ID и Client secret (см. скриншот выше), после чего нажимать Sign in with Google и соглашаться на все.
В имени файла я использовал идентификатор записи в Supabase:
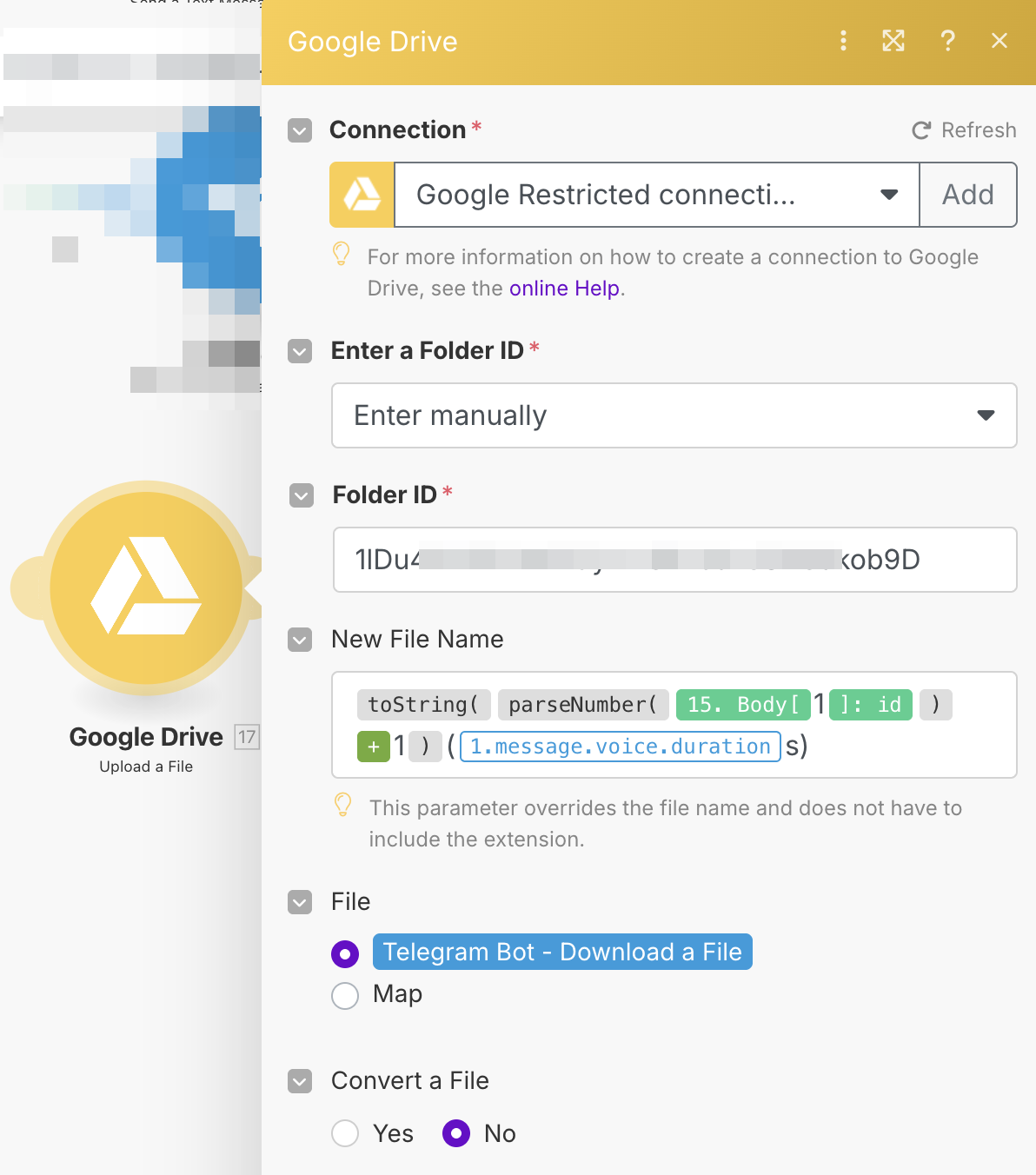
Стоит лишь заметить, что расширение к имени файла добавляется автоматически. В случае аудио из Telegram это расширение — .oga, однако при необходимости файл можно конвертировать прямо в этом блоке (но конвертация будет занимать время).
2.6. Сообщение об успехе
Итак, мы почти у цели — создали почти все блоки в этой цепочке:

Я рекомендую вставить блок Google Drive до сохранения в базу (New record) — чтобы в базе можно было сохранить ссылку на аудиофайл, которую выдаст Google Drive. Если вы сделали в другом порядке, то поменять порядок блоков в Make несложно. Для этого сначала откройте контекстное меню на пунктирной линии, ведущей к блоку Google Drive, выберите в нем Unlink, а затем перетащите этот блок на нужное место — и связи установятся сами.
На схеме осталось только 2 последних не упомянутых блока:
- Блок Data store будет разобран во второй части
статьи. Он служит в данном случае для запоминания идентификатора
созданной записи, чтобы ее можно было отредактировать из Telegram.
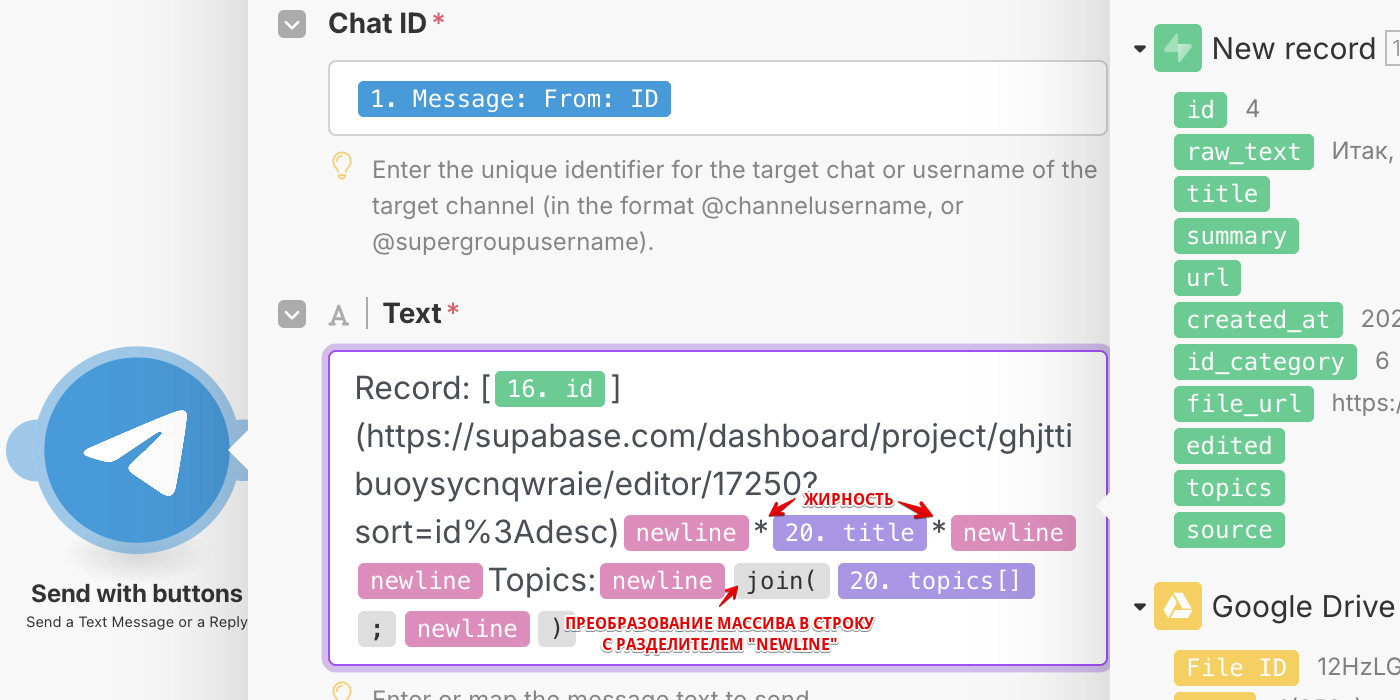
- Блок Telegram / Send a Text Message мы уже разбирали в разделе 2.1, но теперь предлагаю в нем выдать сообщение со всеми нужными вам параметрами созданной записи. Например, у меня это заголовок и категории записи, а также ссылка на Supabase, чтобы запись можно было п��оредактировать или даже удалить.
Продолжение следует
Во второй части статьи я описываю, как подготовить для базы знаний еще 5 типов информации помимо голосовых сообщений:
- свои текстовые заметки,
- телеграм-посты,
- ссылки а) на youtube, б) на гугл-документы, в) на web-страницы.
Разумеется, такой сценарий должен автоматически определять тип входящей информации и по-разному обрабатывать ее в зависимости от типа (и, возможно, от темы). До появления генеративного AI такое было практически невозможно.
No-code-автоматизации — это лишь небольшая часть того, что людям и компаниям можно делать c ИИ. Различные лайфхаки для менеджеров и объяснения трендов ИИ с точки зрения потребностей организации читайте в нашем телеграм-канале.

